


Data residency is about where your data is physically stored, but it doesn’t guarantee compliance or security. Vendors often market "full EU data residency" as a solution, but it may not address legal access, AI data flows, or secondary data processing. For example, even with EU-based storage, U.S. laws like the CLOUD Act can still apply to U.S.-based vendors. Misunderstanding these nuances can lead to compliance risks, as seen with Meta’s €1.2 billion fine in 2023 for transferring EU user data to the U.S.
Key takeaways:
- Residency vs. Sovereignty vs. Localization: Residency is storage location; sovereignty is legal jurisdiction; localization ensures data stays within borders.
- AI Workflows Complications: AI processes like inference or training often involve cross-border data flows, creating compliance challenges.
- Vendor Claims: Vendors may focus on residency while ignoring secondary data flows or metadata storage outside the region.
- Cost of Compliance: Full residency can be expensive and unnecessary unless legally mandated. Alternatives like regional hubs or selective residency can reduce costs.
To evaluate vendors, ask about data flow specifics, sub-processors, and legal jurisdictions. Verify claims with sandbox testing, data flow maps, and encryption key management. Residency is just one part of compliance – understanding the full picture is essential.
Data Sovereignty vs Data Residency Explained: The Compliance Mistake That Costs Millions
sbb-itb-e60d259
What Data Residency Actually Means
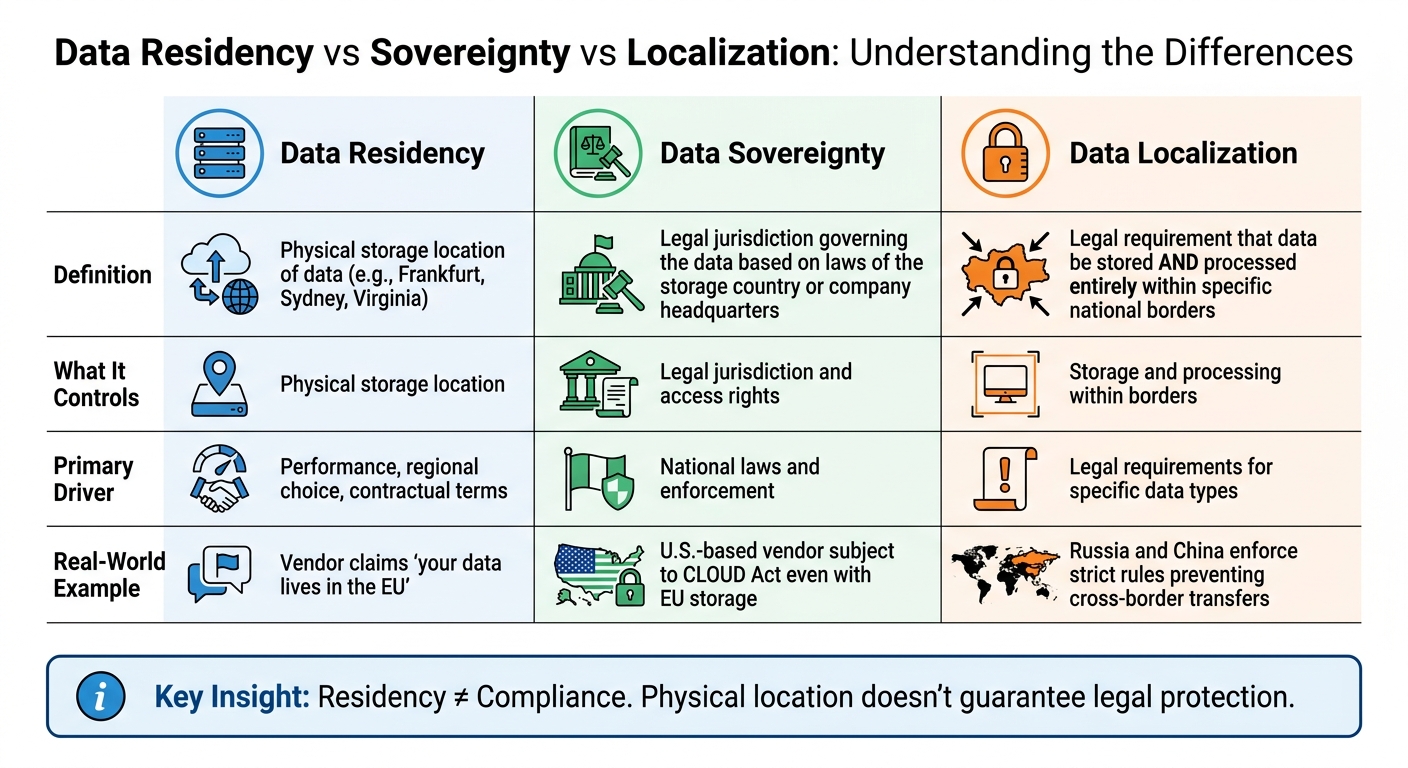
Data Residency vs Sovereignty vs Localization: Key Differences
Data Residency, Sovereignty, and Localization Explained
Data residency refers to the physical location where your data is stored, often described by vendors as being in a specific region like Frankfurt, Sydney, or Virginia. When a company claims "your data lives in the EU", they are talking about residency [8].
Data sovereignty, on the other hand, is a legal concept. It means that data is governed by the laws of the country where it is stored – or sometimes by the laws of the country where the company controlling the data is headquartered. For example, even if your data is stored in Germany, a U.S.-based vendor might still fall under U.S. law, such as the CLOUD Act.
"The legal jurisdiction follows the company, not the data center." – PremAI [1]
Data localization takes things further by requiring that data be stored and processed entirely within specific national borders. Countries like Russia and China enforce strict rules to prevent cross-border data transfers. For instance, in early 2025, TikTok was fined €530 million for transferring EU citizens’ personal data to servers in China [1].
| Concept | What It Controls | Primary Driver |
|---|---|---|
| Data Residency | Physical storage location | Performance, regional choice, contractual terms |
| Data Sovereignty | Legal jurisdiction and access rights | National laws and enforcement |
| Data Localization | Storage and processing within borders | Legal requirements for specific data types |
For support platforms, these distinctions are critical. Simply choosing a local data center doesn’t shield you from foreign government access. For example, in 2024, Microsoft admitted it couldn’t guarantee the sovereignty of UK policing data for Police Scotland. Even though the data was stored in the UK, some processing required moving it offshore, creating compliance challenges [8].
These differences highlight why vendors often emphasize residency in their marketing, even though it doesn’t guarantee full compliance.
Why Vendors Push Data Residency
Vendors focus on data residency in their marketing for two main reasons: regulatory demands and customer concerns. With global spending on sovereign cloud solutions expected to hit $258.5 billion by 2027 [4], residency has become a major selling point.
However, residency is often marketed as a complete compliance solution, which isn’t entirely accurate. Vendors may highlight region selection (e.g., storing data in Frankfurt) as proof of sovereignty, but a U.S.-based provider is still subject to laws like the CLOUD Act.
"Treating data residency as a synonym for compliance is a common mistake. It’s a necessary condition, not a sufficient one." – Eli Mogul, Telnyx [4]
Marketing materials also tend to focus on primary data storage, ignoring secondary data flows. For example, while your support tickets might be stored in the EU, metadata, audit logs, billing records, and AI inference logs could still be routed through non-compliant regions. In August 2024, Uber faced a €290 million fine for transferring sensitive driver data – including criminal and medical records – from the EU to the U.S. without proper safeguards [1].
Encryption is often presented as a solution, but it has its limits. If a U.S.-based provider controls the encryption keys, they can be compelled to hand them over, making the physical storage location irrelevant [9]. By 2030, over 75% of enterprises outside the U.S. are expected to adopt digital sovereignty strategies, up from less than 5% in 2024 [4]. Vendors are aware of these trends and often position residency as the answer, even though it doesn’t fully address compliance needs.
How Residency Affects Daily Operations
Residency rules go beyond marketing and directly impact daily operations, especially in AI-driven support platforms. These policies dictate how data is handled at every stage – from training and inference to fine-tuning and log storage [1].
For instance, when a support agent uses AI to summarize a ticket, the request might be processed in Virginia instead of Amsterdam, even if the primary data is stored in the EU [1]. This is a growing concern, as 73% of enterprises identify data privacy and security as their top AI-related risk [1], yet many fail to audit secondary data pathways.
Here’s a breakdown of how AI-powered support operations typically handle data:
| AI Operation | Data Created | Typical Destination | Default Retention |
|---|---|---|---|
| API Inference | Prompts, completions, metadata | Regional servers | 0–30 days |
| Fine-Tuning | Training examples, model weights | Provider cloud storage | Until deletion |
| RAG/Embeddings | Document chunks, vectors | Vector database (cloud/self-hosted) | Persistent |
| Observability | Full payloads, latency, errors | Monitoring platform | 30–365 days |
Source: PremAI [1]
Residency also affects performance. Hosting data closer to users reduces latency, which is crucial for real-time customer support and AI workflows [10]. But improved speed doesn’t equate to legal protection. For example, in May 2023, Samsung banned internal use of ChatGPT after employees accidentally leaked sensitive semiconductor code and meeting notes into the platform [1]. In such cases, data often passes through multiple systems, from inference APIs to logging platforms and training pipelines.
The gap between vendor promises and operational realities is growing. While 77% of organizations now consider a vendor’s country of origin when purchasing AI solutions [1], many fail to check where secondary data – like inference logs or observability data – actually ends up.
Compliance Requirements That Actually Matter
Regulations That Affect Data Residency
In the U.S., data residency laws vary widely depending on the industry and type of data. There’s no overarching federal law governing where data must be stored, but specific regulations set clear boundaries:
- HIPAA: While it oversees healthcare data protection, HIPAA doesn’t enforce specific geographic storage. Instead, it requires Business Associate Agreements (BAAs) to ensure data protection standards are met, no matter the storage location [9][12].
- ITAR: This regulation is much stricter, mandating that defense-related technical data stays within the U.S. [9].
- FedRAMP: Federal data must be stored in U.S.-based regions within authorized cloud environments [9].
One critical aspect often overlooked is the CLOUD Act (18 U.S.C. § 2713). This law allows U.S. law enforcement to demand data from American companies, even if that data is stored overseas. So, storing data in a Frankfurt data center doesn’t necessarily shield it if your vendor is headquartered in the U.S. [9][7].
State laws, like California’s CCPA, focus more on consumer rights and transparency rather than specifying physical data locations [7][12]. Meanwhile, the DOJ Data Security Program limits the transfer of "bulk sensitive personal data" to countries like China, Russia, and Iran, with penalties reaching $368,136 per violation [12].
For companies handling cross-border customer data, GDPR stands out as one of the strictest frameworks. While it doesn’t require data localization, it imposes tight restrictions on data transfers outside the EU. By 2025, GDPR enforcement had racked up €5.88 billion in fines, including €1.2 billion in penalties issued in 2024 alone [7]. In September 2025, the EU General Court upheld the EU-U.S. Data Privacy Framework temporarily, but ongoing appeals meant companies still relied on Standard Contractual Clauses (SCCs) as a backup [12].
These regulations highlight a key point: distinguishing between legally mandated requirements and strategic decisions around data residency is crucial.
Required vs. Recommended: Understanding the Difference
Data residency requirements fall into two categories: legal mandates and risk management decisions. Unfortunately, vendors often blur this line in their marketing.
- Legal mandates: These are non-negotiable. For example, China’s Data Security Law requires localization for "important data", while India mandates that payment data remain within its borders. Failing to comply can lead to severe consequences, including fines up to RMB 10 million in China, along with potential criminal charges [7].
- Risk mitigation: This involves strategic choices to minimize risks. For instance, choosing an EU data center to reduce GDPR transfer risks is a business decision, not a legal necessity. GDPR allows cross-border transfers as long as safeguards like SCCs or Binding Corporate Rules are in place [9][12].
"Data residency is no longer an infrastructure footnote. It is a design constraint that shapes cloud architecture, vendor contracts, and product roadmaps." – Secure Privacy [12]
The European Data Protection Board has also tightened rules, requiring privacy notices to specifically name third-country recipients. Vague references to "service providers" are no longer acceptable, forcing companies to be more transparent in their disclosures.
For AI-driven support tools, the gap between legal requirements and risk management becomes even more pronounced. While 73% of enterprises rank data privacy and security as their top AI-related concern [7], most AI regulations focus on bias detection and transparency, not geographic storage. For instance, the EU AI Act emphasizes data governance and bias detection but doesn’t mandate data localization. Penalties under this act can reach up to 7% of global turnover [7].
The Real Cost of Compliance
Understanding the financial and operational costs tied to compliance is just as important as knowing the regulations.
Compliance expenses go beyond vendor fees. Organizations face infrastructure costs, legal reviews, and operational constraints that vendors rarely disclose upfront.
- Infrastructure costs: Residency requirements often lead to regional duplication, driving up expenses. Strict localization limits disaster recovery options, forcing businesses to invest in costly in-region redundancies. For example, Oracle’s Dedicated Region starts at $500,000 annually with a minimum four-year commitment [11].
- Legal reviews: These are ongoing and expensive. Transfer Impact Assessments (TIAs) are required to evaluate whether foreign laws adequately protect transferred data. Even with TIAs, companies can face penalties. TikTok, for instance, incurred a €530 million fine due to inadequate assessments [7][12]. Businesses relying on the EU-U.S. Data Privacy Framework should keep executed SCCs ready as a backup for potential legal challenges [12].
Vendor selection has also grown more complex. Seventy-seven percent of enterprises now consider a vendor’s country of origin a key factor when purchasing AI tools [7]. By 2026, 67% of CCaaS contracts are expected to include embedded Generative AI features. However, AI systems introduce unique residency challenges, covering areas like training data, inference computation, and fine-tuning data – all of which require careful evaluation [7].
Operational impacts are equally significant. Running AI inference within a region can be up to 45% faster than cross-region execution [13]. Yet, 67% of enterprises cite data residency as the main barrier to scaling AI systems globally [13]. With 443 GDPR breach notifications reported daily [7], the cost of non-compliance remains alarmingly high.
How Residency Policies Affect AI Workflows
AI Workflow Limitations from Residency Rules
Data residency rules go beyond just determining where files are stored – they also control how data moves during AI processes. This creates immediate hurdles for automated workflows, particularly in customer support.
For instance, when AI is used to generate ticket summaries, detect customer intent, or route cases, data must interact with an AI model. If that model isn’t hosted in the required region, the workflow halts. Take the OpenAI GPT-5 infrastructure as an example: if it’s unavailable in the Danish region by March 2026, you won’t be able to use it for AI features without breaching data sovereignty laws [2]. The only options would be to rely on an older, compliant model or stop using the feature altogether.
Even ephemeral data, which exists for mere milliseconds during AI operations, can fall under these restrictions. Prompts, completions, and embeddings may violate rules if they cross borders, even if they’re not permanently stored [16]. This complicates processes like automated replies, sentiment analysis, and intent detection, as these rely on AI processing in specific jurisdictions.
Residency rules also disrupt "follow-the-sun" support models, where support teams in different time zones handle cases seamlessly. If data can’t cross jurisdictions, support staff lose access to ticket details, making 24/7 service harder to maintain [17]. Cases can no longer be transferred smoothly across regions.
To address these issues, companies are turning to AI Gateways – routing systems that ensure data stays within the appropriate region by directing AI calls to localized APIs. For example, EU data stays within the EU. However, this approach limits access to top-performing global models if they lack local endpoints [16]. The growing concern is evident: inquiries about cloud sovereignty and geopatriation rose by 305% in the first half of 2025, showcasing the scale of this challenge [16]. These limitations also extend into reporting and analytics, which is the next area of concern.
Region-Specific AI Processing and Reporting
Running AI-driven analytics in compliance with residency rules introduces fragmentation issues. To stay compliant, all logging and analytics data must remain local, making global reporting nearly impossible without complex architectural adjustments.
Traditional dashboards that aggregate data across regions often violate residency laws, as they pull raw conversation logs across borders. The workaround? Policy-aware observability – systems that aggregate anonymized performance metrics while keeping raw logs isolated [16][6]. This allows executives to track metrics like resolution times, sentiment, and ticket volume without accessing raw data.
However, this solution has its limits. If customer satisfaction (CSAT) scores drop in Germany, for example, you can’t pull sample tickets from Frankfurt into a centralized platform in Virginia to investigate without breaking compliance rules. This is a major reason why 34% of AI workflow compliance failures stem from improper data exchanges across regions [13].
Federated analytics offers a partial fix. Instead of centralizing raw data, identical queries are run across regions, and only the results are combined. This keeps data local while providing insights. However, maintaining synchronized query logic across regions becomes increasingly complex as new regions are added. These challenges also influence which AI models you can use, as residency requirements limit your choices.
How Residency Limits AI Model Selection
Residency policies don’t just impact workflows and reporting – they also restrict which AI models you can use. These rules act as a barrier by limiting access to certain models based on where they’re hosted. Cutting-edge models aren’t always available in every region, creating a gap between what’s possible and what’s allowed.
Region-specific language models (LLMs) can provide 30% more contextual relevance in specialized fields like law or public services compared to global models [2]. But this advantage is moot if the required model isn’t hosted in the necessary jurisdiction. This issue is widespread, with 67% of enterprises citing data residency as the main obstacle to scaling AI globally [13].
Adding to the complexity is the US CLOUD Act, which allows US authorities to access data stored by US-based providers, even if hosted in foreign regions [15]. This makes many leading AI providers unsuitable for high-risk workflows in the EU, even when they offer regional hosting.
| Feature | Standard SaaS AI | Sovereign/Private AI |
|---|---|---|
| Data Location | Global public cloud (often US-based) | Localized data centers or on-premise |
| Model Selection | Locked to vendor’s provider (e.g., OpenAI) | Choice of local or open-source models |
| Compliance | Risk of foreign access (e.g., US CLOUD Act) | Full jurisdictional control |
| Latency | Optimized for global speed | May have higher latency if local infra is limited |
| Maintenance | Managed by vendor | Higher internal IT responsibility [2] |
To navigate these restrictions, organizations are adopting geopatriation – shifting workloads to EU-based providers like Mistral or Aleph Alpha, or self-hosting open-weight models like Llama or Qwen on sovereign infrastructure [15]. By 2030, Gartner predicts that over 75% of enterprises in Europe and the Middle East will move workloads to sovereign or local solutions [15]. Self-hosting becomes cost-effective at around 2 million tokens per day or 8,000+ conversations [7].
These residency requirements force businesses to make a tough choice: prioritize compliance or leverage advanced AI capabilities. Vendors that design systems with jurisdiction-aware routing – separating sensitive, high-volume operations from less critical ones – offer more flexibility [18]. But the challenge of balancing cutting-edge AI with compliance remains a significant hurdle.
How to Evaluate Vendor Residency Claims
Questions to Ask Every Vendor
Vendors may advertise data residency, but it’s essential to dig deeper and verify their claims. Start by asking which cloud provider and specific regions host your data. A vague answer like "Europe" won’t cut it. You need specifics: Is it Frankfurt on AWS? Amsterdam on Azure? Or a particular GCP zone? Ambiguity can hide the fact that data might be routed to cheaper regions for processing [6][14].
Request a detailed data flow diagram outlining your data’s journey – from ingestion to processing and eventual deletion [6]. Vendors often fail to disclose hidden flows where data is sent to other regions for tasks like transcription, translation, or sentiment analysis [14][7]. Ask directly: "Where are LLM inference calls processed? Is data retained by the LLM provider?" [6].
"Beware of ‘Global’ CCaaS that routes calls via the US for transcription. This violates EU data sovereignty laws."
– Udesk [14]
Demand a complete list of sub-processors, their locations, and their roles in handling your data [6]. Confirm if your data is used for model training and whether you can opt out contractually. Many older Data Processing Agreements (DPAs) lack provisions about using customer data to improve a vendor’s LLM [7].
Legal jurisdiction is another critical factor. US-based vendors are subject to the CLOUD Act, regardless of where the data is stored [7]. As Jaipal Singh, an AI compliance expert, explains:
"The legal jurisdiction follows the company, not the data center."
– Jaipal Singh [7]
This issue is why 77% of enterprises now consider a vendor’s country of origin when making AI-related purchasing decisions [7].
Once you’ve gathered the details, use the checklist below to validate their claims.
Vendor Verification Checklist
After collecting responses, scrutinize the details for inconsistencies or gaps. Use tangible evidence to confirm their commitments:
- Sandbox Testing: Request a sandbox test using real call or chat data to observe how your data is routed before signing any agreement [14]. A 2025 survey revealed that 65% of global CIOs rejected a preferred SaaS vendor because they couldn’t meet data residency requirements [19].
- Console Screenshots: Obtain screenshots showing the exact environment location [19].
- Audit Reports: Review SOC 2 reports to confirm whether the audited environment explicitly includes residency controls [19].
- Encryption Key Management: Ensure encryption keys are managed locally, preventing external control [11].
| Verification Criteria | Standard Cloud Support | Enterprise AI/Sovereign Support |
|---|---|---|
| Data Isolation | Logical separation (multi-tenant) | Physical isolation (single-tenant) or hardware enclaves [6][7] |
| Inference Location | Nearest available GPU | Restricted to specific geographic endpoints [7] |
| Training Opt-out | Manual settings required | Default "Zero Data Training" policy [7] |
| Backup Residency | Global replication for recovery | Regional backups in compliant pairs [5] |
Make sure contracts specify the exact region (e.g., "Frankfurt AWS region") rather than broad areas [19]. The DPA should address AI-specific concerns, such as model training, and confirm that deletion requests extend to backups, caches, and logs [6]. Also, verify whether the vendor provides a certificate of destruction for data purged from all storage locations [6].
Warning Signs in Vendor Responses
While evaluating vendor claims, watch for red flags that could indicate problems:
- Vague "Global" Claims: Vendors who make broad statements about global data localization may not fully understand their architecture – or they could be hiding the real data flows [6].
- Missing Data Flow Maps: If a vendor can’t provide a comprehensive data flow diagram, it might mean they haven’t mapped their sub-processor chain [6].
- Backup Loopholes: Some vendors store primary data in the correct region but keep backups or disaster recovery data in non-compliant locations, risking regulatory issues during failovers [19].
- Support Access Issues: If support teams in other countries can access your data for troubleshooting, this could be classified as a data transfer under regulations like GDPR – even if the primary data remains in-region [19].
- Shared Encryption Keys: Using shared keys increases the risk of cross-tenant data leaks or unauthorized access by the vendor [6].
- Default AI Training: Vendors that automatically use customer data for model training prioritize their development over your privacy [7].
- No Zero Data Retention (ZDR): Without a ZDR option, sensitive prompts and completions could be stored on external servers for weeks [7].
"Data residency for AI isn’t about checking a compliance box. It’s about understanding that every API call, every fine-tuning job, and every RAG query creates data flows with regulatory implications."
– Jaipal Singh [7]
Pay close attention to metadata and control plane leakage. Even if primary data is localized, metadata – like resource names, audit logs, and configuration details – often resides in a global control plane, potentially outside your region. With GDPR fines on the rise, these details are more critical than ever.
When Residency Costs More Than It’s Worth
Determining If You Actually Need Residency
Many organizations overestimate how much data residency they actually need. Residency is often driven by contractual obligations or customer preferences rather than strict legal requirements [5][9]. This distinction is crucial because contractual terms can often be renegotiated, while legal mandates are non-negotiable.
To figure out what you truly need, start by sorting your data into two categories: "Hard Localization" (data that legally cannot leave the country, like in Russia, China, or Vietnam) and "Transfer Restrictions" (data that can move across borders provided safeguards like Standard Contractual Clauses are in place) [5][11]. If you’re not dealing with hard localization laws or regulated data like ITAR or FedRAMP, full residency may not be necessary.
Full localization is expensive because it often requires duplicating entire platforms, which becomes unsustainable unless absolutely required by law [18]. For instance, sovereign cloud solutions like OCI Dedicated Regions often require a minimum 4-year commitment, starting at $500,000 per year [11]. Add to that the cost of premium support – typically around 20% of your total contract value – and the financial burden becomes clear [3].
Beyond the cost, strict residency can also limit flexibility. It often prevents cross-region failover, which reduces system resilience [18]. For many organizations, especially those focused on B2B support, these trade-offs might not make sense unless regulatory compliance absolutely demands it.
This is why aligning residency decisions with your actual operational needs and compliance risks is so important. If full residency isn’t legally required, there are other architectures that can meet compliance standards without the hefty price tag.
Alternatives to Full Residency Compliance
Instead of treating all data as if it needs full residency, consider a selective residency pattern. This involves splitting your architecture into three planes: keeping customer content (like tickets, chat logs, and attachments) local, processing AI inference within the region, and routing control plane data (such as authentication and billing) globally [18]. This approach balances compliance with efficiency.
A great example is Slack’s model, introduced in December 2019. Slack stores customer messages, files, and search indices in specific regions (like Frankfurt), while login requests and member profiles are routed through U.S. data centers. Their Transfer Impact Assessment explains:
"When Users log in to the Customer’s Slack environment, login requests will be sent to the U.S. The authentication process redirects the User to the U.S. data center for the duration of the active session." [18]
This setup allowed Slack to meet EU compliance without the expense of duplicating its entire authentication infrastructure globally, maintaining both compliance and operational reliability.
Other strategies include data minimization – only collecting and retaining necessary data [21] – and using automated Time to Live (TTL) settings to lower storage costs and reduce compliance risks. For analytics and reporting, you can use native warehouse integrations to query data locally, avoiding costly data egress fees [21][14].
Additionally, tools like customer-managed encryption keys (CMK) or external key managers (EKM) can help. By keeping encryption keys within a specific region, you ensure data cannot be decrypted without your explicit control [9][11].
Negotiating Residency Terms with Vendors
If alternative approaches still don’t meet your needs, negotiating with vendors becomes critical. Residency features are often tied to premium service tiers, but these terms are negotiable. Use frustrations with the product or longer-term agreements as leverage to negotiate reductions in the typical 5–15% annual price increases tied to high-tier compliance packages [3].
Push vendors to allow global routing for certain functions like authentication while keeping other data local. For example, in January 2026, OpenAI expanded its residency offerings to include in-region GPU inference for European customers, while still using global infrastructure for authentication and CPU-based routing to maintain performance [18].
It’s also worth negotiating metadata residency. Many vendors store control plane data (like resource names, audit logs, or configurations) globally, even if the main content is stored locally [11]. Ask whether metadata is fully localized and push back on premium pricing if it’s not. Review your Data Processing Agreements (DPAs) carefully – many include "operational continuity" clauses that allow data movement for operational purposes, which could undermine localization. Negotiate to narrow these exceptions or require notification before any cross-border transfers occur [9].
For AI workloads, check if you can opt out of model training. Many older DPAs don’t address whether customer data can be used to improve a vendor’s language model [7].
Finally, consider using data residency-as-a-service providers. These third-party companies specialize in managing regional compliance without requiring you to overhaul your internal systems [20]. This can cut down on costs and reduce the need for specialized IT resources, making it a practical solution for many organizations.
Making Smart Data Residency Decisions
When tackling data residency decisions, the first step is understanding the legal requirements. Many organizations overestimate their needs because vendors often blur the lines between residency (where the data is stored), sovereignty (which country’s laws govern the data), and localization (legal mandates requiring data to stay within a country’s borders) [5][7]. For example, hosting a server in Frankfurt doesn’t automatically mean your data is protected by EU law if your vendor is headquartered in the U.S. and subject to the CLOUD Act [7].
Start by mapping your compliance landscape. Unless you’re operating in countries with strict localization laws – like Russia, China, or Vietnam – you probably don’t need separate deployments in every country [5]. A more efficient strategy is to adopt regional hubs, deploying in 2–4 key locations such as Ireland for EMEA or Singapore for APAC. This approach can help balance compliance needs with cost efficiency [5]. In fact, using regional hubs instead of full localization can reduce compliance costs by up to 25% [22]. Once legal requirements are clear, the next step is ensuring your technology architecture aligns with these regulations.
Daily AI operations also bring residency considerations into focus. Every API call carries regulatory implications [7]. It’s critical to ensure that inference logs, model weights, and observability tools remain within the required geographic boundaries. If your organization processes over 2 million tokens daily, self-hosting large language models can often be more cost-effective than paying extra for managed AI providers offering residency compliance [7]. These operational realities should guide both your technology design and vendor selection.
Be cautious of marketing claims versus actual operational benefits. Confirm where metadata and control plane logs are stored, ensure Transfer Impact Assessments (TIAs) provide reliable conclusions, and verify that encryption keys are managed within the same jurisdiction as your data [11][12]. Remember, residency is a necessary component of compliance, but it doesn’t guarantee full compliance on its own.
Residency-related compliance typically accounts for only 1%–3% of an IT budget [22]. If vendors charge significantly more, it’s worth negotiating. Assess whether the premium reflects genuine risks or compliance needs. Exploring longer contract terms or clarifying which specific services drive the added costs can help you keep operational expenses in line with your actual regulatory requirements.
FAQs
Does EU data residency actually protect me from foreign government access?
EU data residency, while important, doesn’t completely protect your data from access by foreign governments. For example, laws such as the U.S. CLOUD Act enable authorities to request data from companies, no matter where that data is physically stored. This highlights that control and jurisdiction often outweigh the significance of the data’s physical location when assessing protection strategies.
What hidden data flows should I check in AI support features?
Pay attention to hidden data flows like transfers between cloud regions, sub-processors (such as LLM providers), caches, logs, and inference endpoints. It’s also important to analyze how data moves during processing, summarization, and routing – especially across different jurisdictions.
This kind of review helps you spot potential privacy risks and ensures you’re meeting regulatory requirements. By understanding these data flows, you can address vulnerabilities before they become issues.
How can I verify a vendor’s data residency claims before signing?
To check a vendor’s claims about data residency, start by requesting a detailed data flow diagram. This should clearly outline where customer data is stored, transmitted, and processed. Next, ask for relevant certifications, such as ISO or SOC reports, and gather information about their sub-processors and cloud regions. Finally, review their documentation to ensure compliance with laws like GDPR or PIPEDA. Taking these steps helps validate their claims and ensures everything aligns with legal requirements before you commit.







