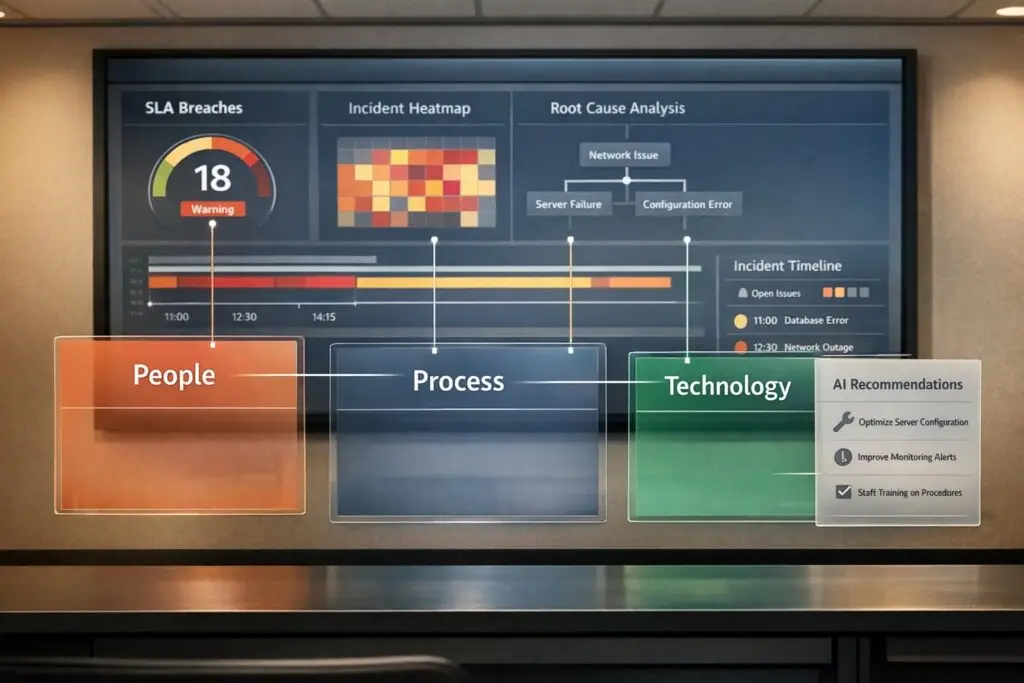
When Service Level Agreements (SLAs) are breached, it’s not just about missed metrics – it’s about broken trust. To fix SLA breaches effectively, you need to identify the root cause and address it properly. Most breaches fall into one of three categories:
- People: Skill gaps, alert fatigue, or staffing issues.
- Process: Poor workflows, unrealistic targets, or missing internal agreements.
- Technology: Automation failures, disconnected systems, or outdated tools.
Here’s the process to tackle SLA breaches:
- Categorize the root cause: Use structured tools like the "Five Whys" or Fishbone Diagrams to determine if the issue stems from People, Process, or Technology.
- Address specific gaps:
- For People: Provide training, automate repetitive tasks, and reduce alert fatigue.
- For Process: Align workflows, improve escalation paths, and set realistic targets.
- For Technology: Upgrade to a modern support CRM, integrate tools, and implement smarter automation.
- Prevent future breaches: Use AI to monitor performance, predict issues, and set early warning thresholds (e.g., 75% and 90% of SLA duration).
SLA Breach Analysis – Process Mining Use Case Series
sbb-itb-e60d259
How to Categorize Root Causes of SLA Breaches

SLA Breach Root Causes: People, Process, and Technology Categories with Indicators and Fixes
To resolve an SLA breach, you first need to identify its root cause. Most breaches fall into one of three categories: People, Process, or Technology. Knowing which of these caused the issue will guide your solution. For example, a people-related issue might require additional training or staffing changes. A process-related problem could mean revisiting policies or improving internal coordination. Meanwhile, a technology issue might call for better system integration or smarter automation.
However, these categories often overlap, making it tricky to pinpoint the exact cause. For instance, a ticket might remain unassigned because the automation rules are too restrictive (a technology issue), but underlying process gaps or skill mismatches could also be contributing factors. In fact, 98% of IT teams report that SLA breaches are frequently tied to automation issues, largely due to disconnected systems [6]. These disconnected systems often obscure deeper problems like inefficient processes or inadequate skills.
"The truth is that having an ITSM tool doesn’t automatically prevent breaches. So, what determines the success of SLAs? It’s the way you set up, integrate, and govern that tool along with how your people and processes align with it." – Suganya, ITSM Evangelist and Product Expert, ManageEngine [6]
To untangle the problem, structured root cause analysis methods like the Five Whys or a Fishbone Diagram can help. These tools push you to go beyond surface-level symptoms – like "the ticket was late" – to uncover the actionable root cause. The table below outlines how to identify the category behind a breach based on specific signs and the potential fixes:
| Root Cause Category | Common Indicators | Fix |
|---|---|---|
| People | Alert fatigue, skill mismatches, slow manual transfers | Training programs, improved staffing, automated triage |
| Process | "Watermelon effect", missing OLAs, unrealistic targets | Policy updates, better internal alignment, vendor management |
| Technology | Misconfigured timers, siloed tools, automation gaps | System integration, AI-driven alerts, CMDB synchronization |
By categorizing the issue correctly, you can implement targeted solutions that restore trust and improve service reliability. Let’s break down each category further to understand their unique indicators and solutions.
People Gaps
People-related issues arise when teams lack the capacity, skills, or awareness to meet SLA expectations. For example, high-priority tickets might get assigned to less experienced agents, or overwhelmed staff may miss critical incidents due to alert fatigue or manual bottlenecks. Understaffing can also delay ticket acknowledgments and updates.
These issues often go unnoticed in dashboards because agents are technically "working", but the quality and speed of their work fall short of SLA requirements. If breaches consistently occur with specific agents, shifts, or ticket types, it’s likely a people-related gap. Addressing this through training, better staffing, or automation can improve response times and reduce breaches.
Process Gaps
Process gaps occur when policies, workflows, or internal agreements don’t align with the realities of day-to-day operations. A common example is the "watermelon effect": SLA metrics look green on dashboards (e.g., timers pause when tickets are marked "on-hold"), but users experience lengthy downtimes, leaving them frustrated. Missing OLAs can also delay team handoffs, eroding accountability. Unrealistic SLA targets – set without considering past performance or team capacity – can lead to frequent breaches. Additionally, third-party dependencies often cause delays that aren’t accounted for in SLA planning.
These gaps are harder to detect because they’re baked into the organization’s workflows. If SLA timers are being met but customers are still unhappy, or if breaches spike during team handoffs, your process likely needs refining. Fixing these issues ensures smoother workflows and clearer accountability.
Technology Gaps
Technology-related gaps arise when systems, integrations, or automation rules fail to support SLA compliance. For instance, misconfigured SLA rules might cause timers to start late, stop prematurely, or fail altogether. Siloed systems can prevent monitoring tools from communicating with the service desk, forcing manual ticket creation when systems go down. Overly rigid automation rules – like those relying on exact keywords – can leave critical incidents unassigned. Reactive monitoring, which alerts teams only after a breach has occurred, further exacerbates the problem.
If your team frequently works around tools rather than with them, you’re likely dealing with a technology gap. For example, an agent might seem slow to respond, but the real issue could be a disconnected monitoring system that failed to generate an alert. Addressing these gaps with better integrations, proactive alerts, and smarter automation reduces manual effort and improves efficiency.
Common SLA Breach Types and Their Root Causes
Now that we’ve identified the three root cause categories, let’s explore how they appear in real-world SLA breaches. Most violations fall into one of three main types: response time, resolution time, and availability breaches. While each has distinct triggers, they often trace back to the same gaps in People, Process, or Technology.
Response Time Breaches
Response time breaches happen when your team fails to meet agreed deadlines for ticket acknowledgment or status updates. This could involve missing the initial response window, delaying escalations between support tiers, or skipping promised status updates [6]. For example:
- During high-volume periods, high-priority tickets might remain unassigned due to agent overload (People gap).
- Manual triage delays can slow down the process (Process gap).
- A lack of automated alerts – such as warnings at 75% or 90% of the SLA duration – can leave agents unaware of imminent breaches (Technology gap) [3][1].
These breaches can erode trust in B2B relationships, where customers expect prompt acknowledgment, even if resolving the issue takes additional time. Next, let’s look at breaches tied to resolution delays and how dynamic SLA management can help prevent them.
Resolution Time Breaches
Resolution time breaches occur when your team fails to fix the issue or restore service within the agreed timeframe [6]. These breaches often stem from:
- Underestimating technical complexity.
- Key personnel being unavailable.
- Dependency chain failures, such as waiting on engineering teams without clear internal SLAs [6][9].
For instance, if a ticket requires backend changes but lacks an Operating Level Agreement (OLA) dictating engineering response times, the ticket may sit unresolved while the customer-facing SLA clock continues to tick [1].
"An SLA you cannot keep is worse than no SLA. If your team consistently misses a 1-hour first response target, you are training customers to expect broken promises." – Jonathan Bar, Founder, Corebee [1]
Resolution breaches often reveal internal bottlenecks, such as unclear escalation paths or insufficient resource allocation. If your team consistently meets response deadlines but struggles with resolution times, it’s worth examining these areas closely.
Now, let’s shift to availability breaches, which often highlight more systemic issues.
Availability and Uptime Breaches
Availability breaches occur when a service fails to meet promised operational levels – such as a guaranteed 99.9% uptime – resulting in excessive downtime [6][9]. These breaches might involve:
- Service outages.
- Interrupted transactions.
- Failures to meet security or data protection standards [6][9].
Unlike response or resolution breaches, availability issues are usually systemic. They may start with outdated server infrastructure (Technology gap), worsen due to ineffective change management (Process gap), and escalate because on-call engineers lack proper training on new protocols (People gap) [5][10].
These are often the most complex breaches, as they involve multiple overlapping causes. For example, an outage might require a structured root cause analysis – using tools like the "5 Whys" or a Fishbone Diagram – to separate contributing factors from the core issue [10].
Understanding these types of breaches provides a strong foundation for applying a step-by-step root cause analysis framework.
Step-by-Step Framework for Root Cause Analysis
Understanding why SLA breaches occur takes more than just looking at a missed deadline. It requires a structured approach that digs into the causes and focuses on preventing future issues. This framework breaks the process into four actionable steps, ensuring you move beyond surface-level reporting.
Step 1: Identify Breaches and Collect Data
The first step is to spot SLA breaches as they happen and gather all relevant data. Your system should capture key details like timestamps, affected customer accounts, ticket IDs, breach duration, and the specific SLA threshold that was exceeded. Using AI-powered alerts can help detect performance issues before they escalate into breaches [5]. For example, if a threshold is close to being violated, early alerts give you time to act.
However, don’t rely only on automated dashboards. Frontline agents often notice patterns of failure before metrics catch up [4]. If agents report recurring problems in ticket workflows, take these observations seriously – even if your dashboards haven’t flagged them yet.
Step 2: Classify the Breach Type
Once you’ve collected the data, classify the breach into one of three categories: response time, resolution time, or availability. This step helps narrow your focus. For instance, a response time breach might point to issues with triage workflows or assignment logic, while a resolution time breach could indicate technical complexities or dependencies. Availability breaches, on the other hand, are often tied to infrastructure or systemic failures. Proper classification ensures your investigation targets the right area.
Step 3: Map to Root Cause Category
Next, determine whether the breach stems from gaps in People, Process, or Technology. This categorization allows you to address the problem effectively. Use a three-level approach:
- Immediate Trigger: What caused the breach right now?
- Process Contributor: Why did the workflow allow it to happen?
- Systemic Driver: Why does this issue keep recurring?
For example, if a ticket breached because no agent was available, that’s the immediate trigger. If the routing rules failed to account for agent workload, that’s the process contributor. And if the problem persists due to poor capacity planning, that’s the systemic driver.
| RCA Step | Focus Area | Objective |
|---|---|---|
| Immediate Trigger | Event Detection | Pinpoint what caused the current breach. |
| Process Contributor | Workflow Analysis | Understand why the workflow allowed the breach. |
| Systemic Driver | Long-term Prevention | Address the root cause to stop recurring issues. |
"Run RCA on your top recurring breach pattern and require one systemic fix, not just one immediate patch." – Red Shore Editorial [4]
Step 4: Segment and Prioritize
Finally, segment breaches by channel, product, team, or customer segment. This helps you identify concentrated problem areas. Use an action tracker with assigned owners, deadlines, and weekly reviews to stay on top of fixes [4]. For instance, if most resolution breaches occur in a specific escalation channel, you’ve pinpointed a key issue.
Focus on breaches with the largest impact – those that affect multiple customers or critical infrastructure components [5]. For example, a breach involving many enterprise accounts should take precedence over isolated incidents impacting individual users.
"The conversation shifts from ‘what happened’ to ‘what changes next week’." – Red Shore Editorial [4]
This segmentation helps you decide whether the solution requires retraining a specific team or overhauling an entire workflow. Once you’ve prioritized, you’ll be ready to implement targeted fixes, as explained in the next section.
How to Fix Each Root Cause Category
When addressing SLA breaches, targeting the root causes within People, Process, and Technology categories is key. By applying specific strategies to each gap, you can significantly improve service outcomes.
Fixing People Gaps
Gaps in the "People" category often stem from issues like skill shortages, unclear roles, or alert fatigue. Tackling these starts with focused training programs that enhance both technical skills and an understanding of SLA objectives. Research shows that ITSM tools can boost SLA adherence to 90% when staff are well-informed about their responsibilities [8].
To address role confusion, assign clear ownership for every step in the service delivery process. For instance, appointing a Customer Success Manager as a point person can reduce ambiguity around SLA terms [8].
Alert fatigue, a common challenge, can be mitigated by leveraging AI-powered alerting systems. These tools filter out irrelevant notifications, leaving only actionable alerts.
"The AI-powered alerting system of New Relic… ensures developers receive only relevant and actionable alerts, minimizing alert fatigue and significantly improving alert quality" [5].
| People-Related Gap | Recommended Strategy | Expected Outcome |
|---|---|---|
| Skill Shortages | Technical and problem-solving training programs | Faster and more accurate issue resolution [7] |
| Role Confusion | Assign clear leads for each workflow step | Reduced missed handoffs [2] |
| Alert Fatigue | AI-based noise reduction systems | Better alert quality and less burnout [5] |
| Misaligned Priorities | Educate stakeholders on SLA impacts | Improved task prioritization [8] |
Fixing Process Gaps
Process gaps often involve unclear escalation paths, unrealistic SLA terms, or errors from manual tracking. Start by automating escalation paths to ensure the right resources are engaged as soon as thresholds are breached.
AI can simplify SLA management by extracting key elements – like uptime requirements or penalties – from contracts and pairing them with real-time monitoring. A notable example is Telecom Solutions Ltd., which, in March 2026, used an AI-native CLM platform to manage 15,000 contracts. By pulling data from over 1,200 fields and integrating it with network analytics, they cut annual penalties by 57%, reduced manual monitoring hours by 1,800 annually, and achieved a 340% ROI in 18 months [11].
Predictive analytics can also forecast breaches 7–14 days before they occur, enabling proactive fixes. Automated systems have demonstrated an 81% improvement in breach detection speed, cutting average detection time from 4.2 days to just 0.8 days [11]. Additionally, implementing a tiered notification system (e.g., Early Warning, High Risk, Imminent Breach) ensures that stakeholders are informed appropriately based on urgency.
Streamlining management reports can save up to 8 workdays per month [8], freeing up time for higher-priority SLA tasks.
"Contract managers found their ‘time and skills more precious for adding value to the business, rather than hustling for some of these clerical routines’" [11].
Fixing Technology Gaps
Technology gaps, such as outdated systems or siloed tools, often underlie systemic failures. Use Pareto charts to identify which components are causing the most issues, and employ service topology maps to visualize dependencies and weak points.
Integrating monitoring tools through APIs and pre-built connectors can create a unified data pipeline, simplifying live analysis. With organizations managing an average of 21 observability tools [12], consolidation is crucial for efficiency.
AI-powered root cause analysis (RCA) can uncover hidden patterns in data with 95% accuracy, compared to 78% for traditional methods [12]. For example, Chipotle Mexican Grill used AI-driven RCA to auto-generate detailed tickets and route them to the right teams, cutting their mean time to resolution by 50% [12].
To handle demand surges or unexpected failures, ensure redundancy in systems and implement backups. AI-driven alerting systems can further reduce false alarms by applying intelligent thresholds and anomaly detection.
"BMW, for instance, leveraged AI-powered RCA and digital twin technology to analyze data from robotic arms, conveyor belts, and alignment sensors – reducing alignment-related production issues by 30%" [12].
| Technology Gap | Identification Method | Resolution Strategy |
|---|---|---|
| Outdated Systems | Pareto charts and historical trend analysis | Decommission old systems or upgrade hardware |
| Integration Silos | API audits and unified data pipelines | Use pre-built connectors for centralized data |
| Alert Fatigue | AI-based noise filtering | Intelligent thresholding and alert correlation |
| System Downtime | Real-time KPI monitoring | Add redundancy and failover mechanisms |
How to Prevent Future SLA Breaches
To prevent SLA breaches effectively, a proactive approach is key. Organizations leveraging predictive analytics have reported a staggering 420% improvement in breach prevention, increasing their proactive handling rate from 15% to 78% [11].
The strategy begins with integrating real-time performance data with contract terms. By using AI to identify patterns that identify at-risk customers proactively, you can shift from reacting to problems after they occur to addressing them before they escalate. For example, monitoring systems that detect breaches 30 minutes in advance allow teams to intervene in a controlled manner rather than scrambling to manage a crisis.
How AI Helps Manage SLAs
AI-powered platforms simplify SLA management by extracting critical elements – like uptime requirements, response time commitments, and penalty clauses – from complex contracts. These platforms then structure the data into a database for consistent monitoring. By pairing this data with live feeds from Network Operations Centers and ticketing systems, performance is checked every 15 minutes, ensuring continuous oversight [11].
Machine learning enhances this process by analyzing historical trends, seasonal variations, and incident patterns to predict breach probabilities. For instance, Telecom Solutions Ltd. adopted an AI-driven contract intelligence system in March 2026 and saw impressive results: a 50% reduction in dispute cases and $2.4 million in avoided penalties within a year. The system’s ability to provide 7–14 days of advance breach warnings gave teams ample time to resolve issues before impacting customers [11].
AI also enables multi-tier alerting systems to notify the right people at the right time:
- Early warnings (30–50% probability): Sent to service delivery managers for monitoring over 72 hours.
- High-risk alerts (51–75% probability): Trigger proactive outreach by operations directors.
- Imminent breaches (76%+ probability): Activate emergency response protocols and involve executives [11].
Beyond alerts, AI can automate remediation tasks, such as increasing capacity or rescheduling maintenance, to prevent breaches. This automation has reduced manual monitoring efforts by 75% and cut detection times from 4.2 days to just 0.8 days [11].
Avoiding Miscategorization and Hidden Breaches
While AI improves monitoring, addressing misclassification is equally important to maintain SLA accuracy. Silent breaches – violations that go unnoticed due to ambiguous definitions or inconsistent tools – pose a significant risk.
To tackle this, implement a severity classification matrix that evaluates breaches based on factors like the number of users affected, business impact, and duration. Set tiered warning thresholds at 75% and 90% of SLA duration to enable early intervention [3].
Another critical step is tracking how breaches are detected. If customers report issues before your systems do, it highlights a visibility gap [3]. AI-powered anomaly detection can help by establishing performance baselines and flagging deviations that might indicate hidden problems [5].
Additionally, frontline staff often notice failure patterns before automated systems. Incorporate their observations into root cause analyses using tools like the "5 Whys" or fishbone diagrams. These methods can uncover deeper issues, such as staffing shortages or process inefficiencies, that contribute to SLA breaches [3][4].
Finally, conduct post-breach reviews for all high-severity incidents within a week of resolution. Use these reviews to document lessons, assign responsibility for corrective actions, and track whether those actions prevent repeat issues. Organizations that adopt structured breach management practices typically reduce escalation cycles by 30–40% and cut repeat SLA breaches by 25–35% [3].
Conclusion
Breaking down root causes into clear categories – People, Process, or Technology – helps teams shift from constantly reacting to problems toward solving them at their core. By categorizing breaches, you stop addressing just the symptoms and start tackling the underlying reasons for failures. This approach transforms chaotic, reactive support operations into a system focused on consistent customer experiences [4][2].
The results speak for themselves. Metrics show that structured frameworks can cut down on escalation cycles and prevent repeat breaches [3]. Case studies highlight how organizations using AI-driven methods have not only avoided significant penalties but also seen impressive returns on investment [11].
"Fixing the source keeps the same issues from coming back in the next sprint, release, or quarter." – Slack [2]
Modern AI tools enhance this process by analyzing up to 15,000 metrics per second, delivering 95% accuracy in identifying root causes compared to the 78% achieved by traditional methods [12]. However, technology alone doesn’t solve everything. The real game-changer is combining AI-powered monitoring with structured processes – like setting tiered alert thresholds at 75% and 90% of SLA timelines, implementing systemic fixes for recurring issues, and validating changes to ensure they stick [3][4].
FAQs
How do I determine if an SLA breach is caused by people, process, or technology?
To figure out why an SLA breach happened, you’ll need to conduct a root cause analysis (RCA). Start by identifying the immediate trigger – what caused the breach right at that moment? Then, dig deeper to see if workflow bottlenecks or procedural gaps played a role. Finally, evaluate whether recurring technology failures or system limitations contributed to the issue.
This step-by-step approach helps you determine if the breach was due to human error, process flaws, or system-related problems. Once you know the root cause, you can focus on implementing precise solutions.
What data should I capture to run an SLA root cause analysis fast?
To effectively conduct an SLA root cause analysis, it’s crucial to collect and examine data that pinpoints the issue, identifies contributing factors, and uncovers deeper, underlying causes. Key areas to focus on include:
- Immediate triggers: Determine what directly caused the SLA breach.
- Process details: Review the workflows or steps that were in play when the issue occurred.
- Systemic drivers: Look for patterns like recurring problems or resource shortages that might have contributed.
- Evidence: Gather concrete data, such as timestamps, affected services, and the extent of customer impact.
- Dependencies: Understand how upstream or downstream processes were affected.
- Frontline agent input: Leverage insights from those directly involved for an early understanding of the situation.
By addressing these areas, you can ensure a comprehensive and efficient analysis.
How can AI predict SLA breaches early without creating more alert noise?
AI helps predict SLA breaches by analyzing patterns in operational data, allowing teams to address potential problems before they escalate. Using historical and real-time data, predictive analytics tools pinpoint high-risk situations, cutting down on irrelevant alerts and concentrating on meaningful risks. On top of that, AI-powered automation prioritizes and filters alerts based on urgency and the likelihood of a breach. This reduces unnecessary noise, enabling teams to focus on resolving critical issues more effectively, which boosts operational performance and enhances customer satisfaction.