


Duplicate tickets waste time, distort metrics, and complicate workflows. But overly strict deduplication can hide important issues, especially in B2B support where context varies across stakeholders. To build effective rules:
- Balance strictness and flexibility: Use exact matches for clear duplicates but apply fuzzy matching with caution.
- Protect critical cases: Flag escalated or high-priority tickets for manual review instead of auto-merging.
- Leverage AI: Tools like sentiment analysis and similarity scoring improve accuracy, catching nuanced duplicates.
- Test and monitor: Start with historical data, track metrics (like false negatives and rollback rates), and refine rules regularly.
The goal is to save time, maintain accurate data, and ensure no key issues are overlooked.
AI Finds & Merges Duplicate Records Automatically (No Matching Rules Needed!)
sbb-itb-e60d259
Common Problems with Case Deduplication
Case deduplication often stumbles due to overly simplistic rules that fail to address the complexity of B2B support systems. Many systems assume their built-in duplicate handling is sufficient, but these standard rules rarely account for the nuances of B2B environments. Worse, they often provide vague error messages, leaving users unsure about what went wrong [3]. This leads to two major issues: inappropriate merging of cases and unchecked duplicates.
"At a leadership level, duplication is usually framed as an annoyance rather than something worth measuring or fixing." – Tim, Manager of Customer Support, Cars.com [1]
Even a short delay caused by duplicate handling – just 1 to 3 minutes per case – can disrupt an agent’s workflow, fragment service delivery, and distort performance metrics [1]. In B2B scenarios, the problem escalates. For instance, both an admin and an end user might submit tickets for the same issue, or tickets for entirely different problems might be incorrectly grouped because automated rules rely solely on an Account ID [1].
When Merging Rules Are Too Strict
Strict deduplication rules can lead to merging cases that should remain separate, causing confusion and loss of critical context. For example, fuzzy matching might mistakenly combine tickets for "Tech Company UK" and "Tech Company North America", even though they represent different branches with unique support needs [3]. Similarly, addresses like "100 N Main St" and "100 S Main St" might be treated as the same location, merging unrelated records [3].
Timing thresholds can also cause problems. For instance, tickets submitted hours apart – especially after an escalation – might be automatically merged despite containing entirely different contexts [1].
"Merging tickets can introduce risk or confusion… judgment replaces process and reporting struggles to reflect what actually happened." – Tim, Manager of Customer Support, Cars.com [1]
These examples highlight the risks of relying too heavily on rigid rules without considering the need for flexibility.
Finding the Right Mix of Automation and Manual Review
Automation is excellent for handling repetitive tasks, but it falls short when interpreting intent or addressing edge cases. While it can process large volumes of "noise", it struggles with high-value accounts or cases requiring a nuanced understanding [2]. Automated systems often discard important contextual metadata – such as file paths, names, dates, or BCC fields – which can lead to missed details if those elements are critical for identifying duplicates [4].
To address this, consider introducing a review queue for low-confidence matches. Set a similarity score threshold that triggers this queue instead of automatically merging cases. For fuzzy or uncertain matches, configure the system to alert agents rather than taking action, allowing them to make informed decisions [3]. By combining automated detection with manual oversight, you can ensure that even subtle, context-specific issues are handled appropriately [3].
How to Set Up Deduplication Rules That Work
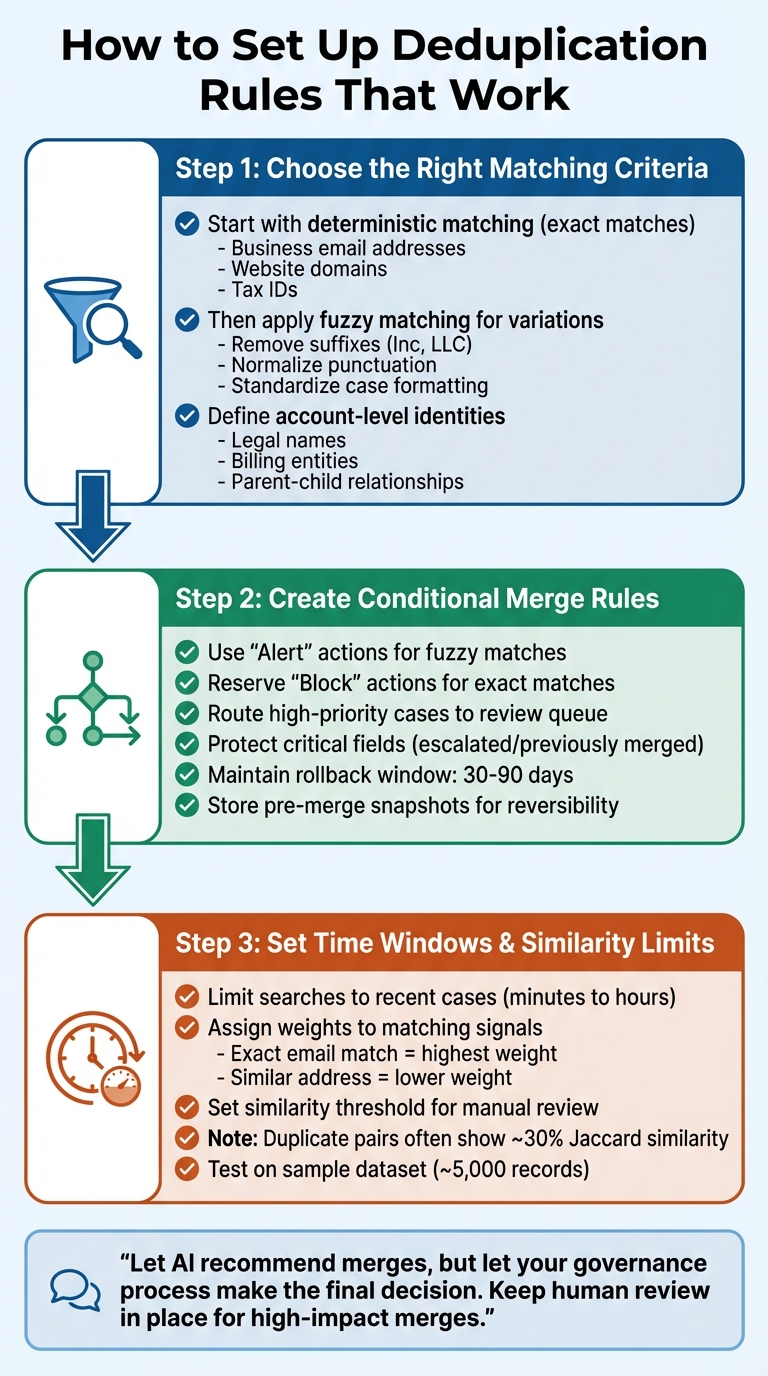
3-Step Guide to Implementing Effective Case Deduplication Rules
Creating effective deduplication rules requires a balance between catching actual duplicates and avoiding the merging of distinct cases. To achieve this, you need to layer logic, protect escalations, and set clear boundaries for automation. Here’s a step-by-step guide to refine your deduplication process with matching criteria, conditional merge rules, and time-based filters.
Step 1: Choose the Right Matching Criteria for B2B Cases
Start with deterministic matching – this involves exact matches using unique identifiers like business email addresses, website domains, or tax IDs. These matches should run first to identify clear duplicates and reduce the dataset size before applying more complex logic [2]. For example, if two cases share the same email domain and reference the same product instance ID within a short time, it’s a strong indicator of a duplicate.
Once the exact matches are handled, move on to fuzzy matching to catch variations. This approach involves techniques like removing suffixes (e.g., "Inc" or "LLC" from company names), normalizing punctuation, and accounting for common variations in names. Before calculating similarity scores, ensure the data is standardized – this includes case formatting, whitespace, and punctuation [2][7].
"The situation is made harder because every organization defines ‘duplicate’ differently."
– Stacy O’Leary, Salesforce Consultant [3]
For B2B cases, it’s essential to define account-level identities. This includes details like registered legal names, billing entities, and parent-child account relationships. Use domain capture to automatically link new contacts to existing accounts based on their email domains [2]. This prevents fragmented case histories caused by multiple contacts from the same company.
After setting up these matching criteria, integrate them into conditional merge rules to handle high-priority cases with care.
Step 2: Create Conditional Merge Rules with Escalation Protection
Not all matches should result in automatic merges. Overly strict rules can compromise critical case context, so it’s important to use a layered approach. For example, use "Alert" actions for fuzzy matches to notify agents without blocking case creation. Reserve "Block" actions for exact matches where duplicates are certain [3]. For high-priority accounts or cases with high similarity scores, route potential matches to a review queue for manual decisions [2].
"Let AI recommend merges, but let your governance process make the final decision. Keep human review in place for high-impact merges."
– Routine [2]
Critical fields should be protected, and cases flagged as escalated or previously merged should be excluded from automated processes [2][5]. To avoid oversights, enforce mandatory duplicate checks before closing cases [5].
For added safety, maintain a rollback window of 30–90 days for high-priority merges. This allows recovery if a false match is identified later [2]. Always store pre-merge snapshots to map old IDs to new records, ensuring reversibility. As of March 2026, maintaining detailed audit logs for all merge activities is crucial for compliance with evolving data privacy regulations [2].
Step 3: Set Time Windows and Content Similarity Limits
Time-based filters are key to avoiding irrelevant comparisons with older data. In B2B support, most duplicates occur within short timeframes – typically minutes to hours rather than days or weeks [6][8]. Limit duplicate searches to recent cases, aligning with your typical ticket resolution times [2].
When evaluating content similarity, assign weights to matching signals based on their importance. For example, an exact email match should carry more weight than a similar physical address [2][7]. Set a similarity score threshold that flags borderline cases for manual review instead of automatic merging. Research shows that duplicate pairs often have low Jaccard similarity scores (around 30%) in text-based records [6].
To manage computational costs, use techniques like blocking or Locality Sensitive Hashing (LSH) to group records with shared features before applying detailed similarity calculations. Test your matching rules on a sample dataset (around 5,000 records) to fine-tune thresholds [2].
Using AI to Improve Duplicate Detection
AI-powered deduplication takes a smarter approach compared to traditional rule-based systems. Instead of relying on rigid "if-then" rules, AI evaluates the full context of each case – looking at subject lines, descriptions, and even customer interaction history. By recognizing patterns and learning from historical data, AI can grasp the intent behind a customer’s message [9][11]. This makes it possible to detect duplicates even when customers describe the same issue in different ways across multiple submissions.
One standout feature is sentiment analysis, which helps differentiate between a routine follow-up and a new, urgent issue that might initially seem like a duplicate [11]. For instance, if a customer submits a case that looks like a repeat but their tone has shifted from neutral to frustrated, sentiment analysis ensures the issue gets flagged for manual review. This approach ensures that evolving customer concerns don’t get lost in automated workflows, paving the way for more accurate duplicate detection.
How AI Finds Similar Cases More Accurately
Modern AI tools like Large Language Models (LLMs) and embedding vectors have significantly boosted deduplication accuracy. Data scientist Ian Ormesher observed that using GenAI methods nearly doubled deduplication accuracy – from 30% to almost 60% [12]. These models embed case data into high-dimensional spaces, where similarities are measured using techniques like Cosine Similarity [12].
"On common benchmark datasets I found an improvement in the accuracy of data de-duplication rates from 30 percent using NLP techniques to almost 60 percent using my proposed method."
– Ian Ormesher, Data Scientist [12]
By integrating methods like Double Metaphone for phonetic matching with LLM-driven reasoning, AI systems can identify potential matches more effectively. They assess the overall context of a case rather than focusing solely on isolated fields [13]. Beyond just detecting duplicates, these AI systems also help streamline case management by automating repetitive tasks.
Automating Case Prioritization and Tagging
Once duplicates are identified, AI takes it a step further by optimizing workflows through automatic prioritization. AI evaluates case details and customer history to assign priority levels [10]. This ensures that critical issues, such as those involving high-value accounts or upcoming renewals, stay at the forefront – even if flagged as duplicates.
Automated tagging is another game-changer. AI categorizes cases into groups like "Bug", "Billing", or "Feature Request", creating a consistent structure for case management [9]. Unlike manual tagging, which can be inconsistent, AI uses historical patterns to apply tags accurately. This makes it easier to identify recurring issues and spot duplicate trends without relying on agents to recall past cases.
AI also simplifies the review process with case summarization, condensing lengthy interaction threads into concise overviews. This helps agents quickly determine whether a new ticket is a true duplicate or a separate issue that needs attention [11]. This feature is especially helpful in B2B support, where cases often involve multiple interactions and long conversations.
How Supportbench Uses AI for Deduplication
Supportbench incorporates these advanced AI capabilities to improve B2B support workflows. Its sentiment analysis detects emotional shifts in customer interactions, allowing teams to prioritize cases from frustrated customers [11]. When combined with deduplication, this ensures that high-frustration cases receive immediate human attention, even if they resemble existing tickets.
Supportbench also uses predictive CSAT scoring to estimate customer satisfaction levels for incoming cases [11]. If a duplicate case is flagged with a low predicted CSAT score, it signals growing customer dissatisfaction and triggers proactive escalation.
The platform’s auto-tagging feature ensures that even potential duplicates are properly categorized and prioritized based on their content [9]. Additionally, Supportbench integrates with knowledge bases to suggest relevant articles during the deduplication process. This ensures consistent responses across related cases while maintaining a clear record of the original issues. For real-time efficiency, AI assistants can flag possible duplicates as soon as a new case is submitted, enabling agents to merge or dismiss them immediately [14].
Supportbench’s AI tools are highly customizable, allowing teams to adapt features to their specific workflows without needing IT support. This flexibility ensures that deduplication processes align perfectly with each organization’s unique needs.
Testing and Tracking Deduplication Performance
Test Rules with Historical Cases First
Start by testing your deduplication rules on a sandbox dataset of around 5,000 historical records. This helps identify both false positives and duplicates that might go unnoticed [2]. Use a step-by-step approach: begin with strict, deterministic matching to set a baseline, then layer in fuzzy or AI-driven logic to handle variations [2].
It’s also smart to set up a review queue for low-confidence matches. Flagging these for manual confirmation prevents auto-merging errors, which is especially important for high-value accounts where incorrect merges could obscure critical issues [2]. Once you’re confident in the accuracy of your rules, shift your focus to tracking their performance with specific metrics.
Metrics to Track Deduplication Success
After validating your deduplication rules, measure their success using key performance indicators. One important metric is match precision, which shows how often duplicates are identified correctly versus how often errors occur. A low rollback rate – a measure of how often merges need to be undone – indicates stable rules. On the other hand, a high rollback rate suggests your matching criteria need adjustment [2].
Another critical metric is the false negative rate, which tracks how many duplicates go undetected. Additionally, analyze duplication rates by category. For example:
- Billing issues often have a duplication rate of 5–8%.
- Incident-related tickets can spike to 25–40% during outages.
- Access-related issues usually fall in the 10–15% range [1].
These benchmarks help you identify where deduplication efforts are most impactful and where your rules might need fine-tuning.
Keep an eye on Average Handle Time (AHT) distortion. Duplicate tickets typically take just 1–3 minutes to resolve, which might make AHT metrics look better than they actually are. This can hide inefficiencies in your workflows [1].
"The cost of duplicate tickets doesn’t need to be perfectly measured to be taken seriously. It just needs to be understood well enough to act." – Tim, Manager of Customer Support, Cars.com [1]
Finally, monitor improvements in first-response time to see how removing duplicate noise allows agents to address genuine issues more quickly.
Conclusion
Keeping duplicates under control requires a thoughtful mix of AI-driven tools and human oversight. The best results come from blending AI’s ability to spot patterns with human judgment, especially in B2B scenarios where context often outweighs volume.
"The definition of what a ‘duplicate’ is differs by organization… That’s why deduplication takes careful planning and continuous monitoring" [3]
This balance is crucial in complex environments. Without careful oversight, critical issues can get lost or hidden, particularly in B2B accounts where merging errors might obscure important escalations or systemic patterns.
AI tools like Supportbench play a key role by learning from historical data and detecting patterns that manual processes might overlook [11]. However, technology alone isn’t enough. Regular reviews are essential – monitoring rollback rates, identifying false negatives, and fine-tuning thresholds as business needs shift.
As businesses evolve – whether through changes in naming conventions, new product launches, or shifts in customer communication – deduplication processes must adapt. Regular audits and updates ensure rules stay relevant. Simple practices like setting up review queues for uncertain AI matches, maintaining audit logs for compliance, and assigning responsibility for weekly duplicate reports can help keep customer issues front and center.
The payoff? Faster response times, more reliable metrics, and fewer genuine customer concerns buried under duplicate clutter. In the end, accurate deduplication doesn’t just streamline operations – it safeguards the quality of customer interactions.
FAQs
How do I decide what counts as a duplicate in B2B support?
To spot duplicates in B2B support effectively, start by setting clear criteria. Focus on key identifiers like requester email addresses and ticket subjects to pinpoint overlaps.
AI tools can take this a step further by using semantic analysis and intent matching, which helps recognize duplicates even when the wording differs. However, it’s essential to balance automation with manual review. Over-relying on automation could lead to overly aggressive merging, potentially masking real customer issues.
By combining these approaches, you can address duplicate tickets while keeping visibility into the root problems your customers are facing.
What cases should never be auto-merged (like escalations or high-priority cases)?
Cases like escalations and high-priority tickets demand personal attention and should never be merged automatically. These situations require thorough handling to ensure critical issues are resolved effectively and no essential details are overlooked. If these cases are auto-merged, vital context could be lost, leading to unresolved problems or missed escalations, which could negatively affect operations or customer satisfaction.
Which metrics best prove our deduplication rules are working?
Key measures of success involve lower duplicate ticket volume, reduced agent handling times per ticket, and better support metrics such as SLA compliance and customer satisfaction. These results highlight a decrease in fragmented tickets and smoother resolution workflows.







