


In B2B support, focusing on the quality of your knowledge base is far more impactful than just increasing the number of articles. High-quality content ensures faster ticket resolutions, better AI performance, and improved customer satisfaction. Here’s the key takeaway: quality drives outcomes, not quantity.
Why Quality Matters:
- Outdated or incomplete content frustrates customers and reduces trust.
- 91% of customers would use a knowledge base if it met their needs, but 40% still contact support after failed self-service attempts.
- Metrics like accuracy, completeness, timeliness, uniqueness, clarity, and metadata correctness are critical to creating effective knowledge.
Steps to Improve Knowledge Quality:
- Define a Quality Rubric: Use metrics like accuracy, relevance, and impact to evaluate content.
- Leverage AI Tools: AI can review 100% of content for readability, accuracy, and gaps, reducing manual workload.
- Tie Quality to Support Outcomes: Link quality scores to metrics like resolution time, First Contact Resolution (FCR), and key customer experience metrics.
- Maintain Regular Updates: Automate review cycles to keep content current and relevant.
- Measure Contributor Impact: Focus on how often content resolves cases, not just volume.
Teams prioritizing quality over quantity save time, enhance AI effectiveness, and deliver better customer experiences. Start small, measure consistently, and let data guide improvements.
Key Dimensions of Knowledge Quality in B2B Support
6 Knowledge Quality Dimensions & Their Business Impact in B2B Support
Core Dimensions of Knowledge Quality
Not all knowledge gaps are created equal. An article might be factually correct but still difficult for agents to use. Or it could be well-written but outdated, rendering it ineffective. Identifying which aspect of quality is lacking allows you to address the specific problem at its root.
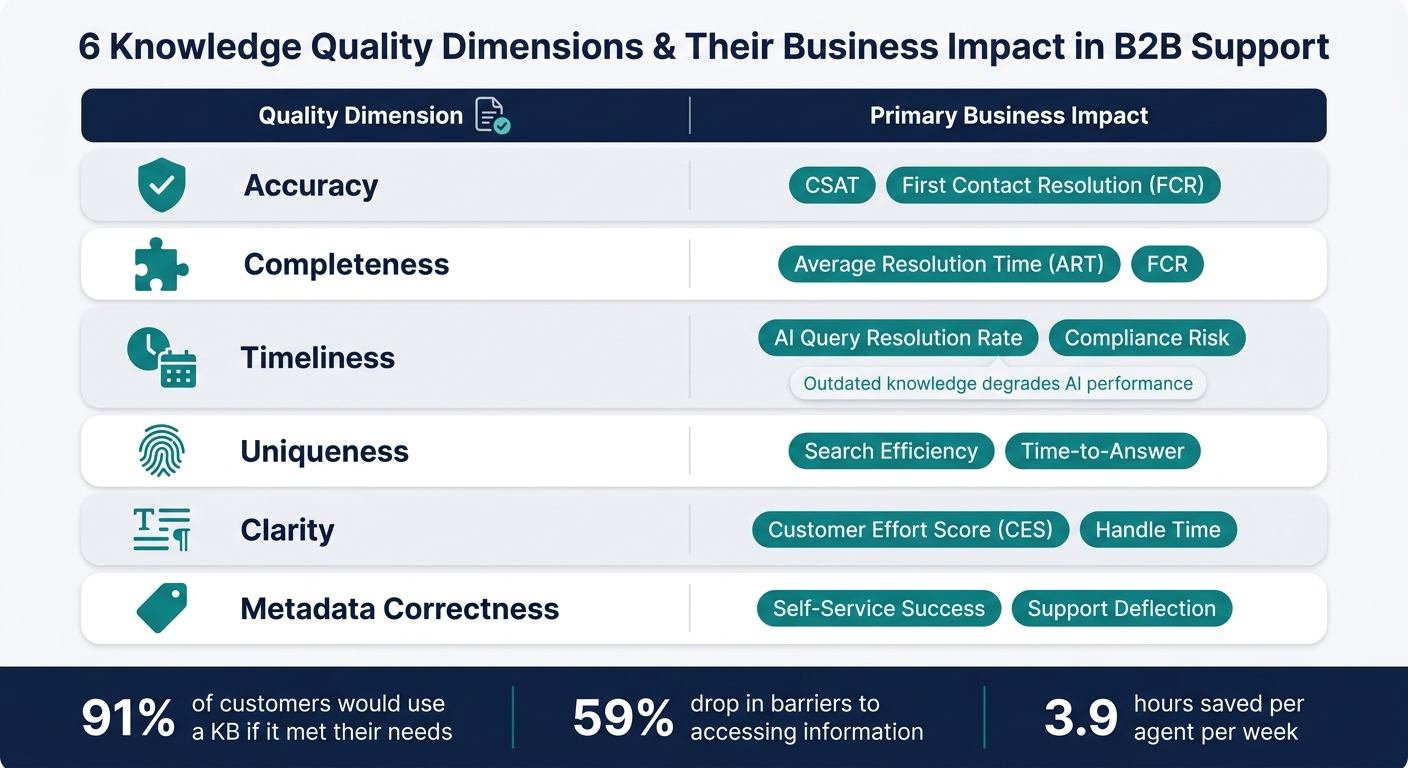
In B2B support, six dimensions stand out: accuracy, completeness, timeliness, uniqueness, clarity, and metadata correctness. Here’s what each entails:
- Accuracy ensures the solution works in the customer’s specific environment, not just in theory.
- Completeness means the article doesn’t just address the issue but also includes the operating context, root cause, and resolution. Missing details force agents to dig for more information, which slows down resolutions and creates inconsistencies.
Timeliness is especially important in AI-driven support systems. As Betsy Anderson, Certified Knowledge Manager at Bloomfire, explains:
"Outdated knowledge doesn’t just mislead employees, it actively degrades the performance of AI-powered features." [3]
Uniqueness eliminates duplicate articles, which can confuse agents and undermine their confidence. Clarity ensures articles are structured and easy to follow, avoiding jargon or shorthand that only seasoned agents might understand. Lastly, metadata correctness – accurate tagging and audience targeting – helps ensure content reaches the right people at the right time. These dimensions are essential not just for human agents but also for AI systems.
Each of these quality dimensions plays a critical role in improving support outcomes, as detailed below.
Connecting Quality Dimensions to Business Outcomes
The quality of knowledge directly impacts key support metrics. For example, incomplete articles lead to longer Average Resolution Times (ART) as agents scramble to gather missing information. Outdated content increases compliance risks and reduces AI query accuracy. Poorly written articles can elevate the Customer Effort Score (CES) and prolong handle times.
| Quality Dimension | Primary Business Impact |
|---|---|
| Accuracy | CSAT, First Contact Resolution (FCR) |
| Completeness | Average Resolution Time (ART), FCR |
| Timeliness | AI Query Resolution Rate, Compliance Risk |
| Uniqueness | Search Efficiency, Time-to-Answer |
| Clarity | Customer Effort Score (CES), Handle Time |
| Metadata Correctness | Self-Service Success, Support Deflection |
Organizations that excel in knowledge management report a 59% drop in barriers to accessing information. They also save employees an average of 3.9 hours per week in search time [3]. That’s almost half a workday reclaimed per agent each week – just by ensuring content is accurate, up-to-date, and easy to find.
sbb-itb-e60d259
How to Build a Framework for Measuring Knowledge Quality
Start with Baseline Metrics
Begin by gathering baseline data to provide context for your quality scores. Look at metrics like engagement, effectiveness, search performance, internal contribution, and operational impact to pinpoint areas that need improvement [1]. Pay special attention to "searches with no results" to uncover content gaps and "linked articles per ticket" to assess how often knowledge is applied in live scenarios [1]. A practical way to ensure consistent tracking is by requiring agents to link relevant help articles as part of their ticket-handling process. This makes knowledge usage measurable and reliable [1].
This foundational data creates the groundwork for building a quality scoring system.
Build a Quality Scoring Rubric
With your baseline metrics in place, the next step is defining what "quality" means for your knowledge base. A scoring rubric provides a consistent framework for reviewers – whether human or AI – to evaluate content. Your rubric should align with key quality dimensions: Accuracy & Freshness, Relevance, Impact, Adherence, and Utility. Each dimension needs clear, measurable criteria.
| Quality Dimension | Evaluation Criterion | B2B Application |
|---|---|---|
| Accuracy & Freshness | Average article age / update frequency | Technical steps must reflect the current software version |
| Relevance | Helpfulness score / search CTR | Article title and content should match the user’s actual search intent |
| Impact | Ticket deflection rate / CES | Content should prevent support contacts and reduce customer effort |
| Adherence | Process adherence rate | Authors should follow internal style guidelines and tagging taxonomy |
| Utility | Linked articles per ticket | Agents should find the content valuable enough to use during live cases |
To maintain content freshness, set up automated alerts for articles that haven’t been updated within a specific timeframe – such as quarterly for policy documents or annually for how-to guides. This ensures updates don’t depend solely on manual reviews [3].
The next step is to link these quality scores to support performance data, proving their impact on business results.
Connect Knowledge to Support Performance Data
Once you’ve established quality metrics, tie them to support outcomes to demonstrate their value. For example, reliable content improves AI accuracy, helpful articles boost First Contact Resolution (FCR), and better search-to-find ratios lower Customer Effort Scores (CES) [1][3]. If low-rated articles correlate with more escalations or longer resolution times, it becomes clear that improving content quality is essential.
Eric Klimuk, Founder and CTO of Supportbench, highlights this point:
"If you’re reporting on volume without context or measuring time without linking it to customer satisfaction, you’re just busy, not improving." [5]
To make this connection, analyze your case data and support metrics. Track which articles are linked to resolved tickets, then compare resolution times and customer satisfaction scores for cases where knowledge was used versus those where it wasn’t. This data-driven insight provides a compelling case for prioritizing knowledge quality instead of just increasing the quantity of content.
Using AI to Evaluate Knowledge Quality at Scale
AI-Driven Content Assessment
Manual reviews can only cover a fraction of the workload. Most support teams manage to manually review just 2–5% of their total ticket volume [4], leaving a massive portion of knowledge interactions unchecked. AI, however, can analyze 100% of your content.
At the article level, AI tools can evaluate readability, structure, and SEO performance by analyzing factors like sentence length, paragraph structure, subheading distribution, and metadata completeness [6]. This analysis generates a "Readability Score" for each article, offering content managers clear indicators of which pieces need adjustments to reduce friction for both customers and agents.
AI also ensures content accuracy by cross-referencing factual claims – such as plan details or refund policies – against your existing knowledge base or account data [4]. Tools like Supportbench’s AI-powered article creation, which draws from resolved case histories, further help reduce inconsistencies or inaccuracies.
Another useful quality metric is the AI draft edit rate – the percentage of AI-generated responses that agents modify before sending. Ideally, this rate should stay below 20% [2]. If agents frequently revise drafts tied to a specific article, it’s a sign that the article might need updates.
"The AI can only be consistent if the knowledge base is consistent." – Relay Team [2]
These measurable insights enable real-time monitoring, helping teams identify and address issues that could affect customer experience.
Monitoring Knowledge Impact in Real Time with AI
Building on content assessment, real-time AI monitoring connects article quality directly to customer satisfaction. Once AI begins scoring content quality, these scores can be linked to customer experience metrics as cases unfold – eliminating the need to wait for survey results.
One standout application is Predictive CSAT. By analyzing tone, completeness, and resolution quality in real time, AI can predict satisfaction levels before a customer even fills out a survey. For example, Supportbench’s Predictive CSAT feature displays this data within the case list, enabling team leads to intervene in at-risk cases immediately.
"Low QA scores on Monday’s tickets predict low CSAT responses on Wednesday. You can intervene before the survey results come in." – Supp Blog [4]
AI models demonstrate 85–90% agreement with human raters on factors like tone, empathy, and professionalism [4]. To ensure reliable results, aim for AI-human agreement rates above 80% across all quality dimensions before fully automating scoring processes.
Automating Quality Review Workflows
Keeping a large knowledge base updated without overwhelming your team requires automation. Instead of relying on manual reminders, AI can trigger "review pending" flags for articles that haven’t been updated in 90 days [2]. This systematic approach helps combat content decay.
AI doesn’t just rely on time-based triggers. It can also identify low-quality content by clustering unanswered queries and low-confidence search results, highlighting knowledge gaps [7]. If agents repeatedly struggle to find information, AI detects the pattern before it impacts customer satisfaction scores.
An effective automation strategy can follow this layered approach:
| Review Cycle | Key AI-Driven Actions |
|---|---|
| Weekly | Flag top-cited articles with declining helpfulness scores; process agent-flagged update requests [2] |
| Monthly | Audit content freshness and analyze gaps from unanswered queries [2] |
| Quarterly | Perform a full knowledge base health check and recalibrate AI scoring models using human-reviewed samples [2] |
For SaaS products with frequent updates, a 60–90 day content freshness half-life is a practical benchmark. Articles older than this should be automatically queued for review [7]. This automation reduces manual workload, ensuring critical content stays relevant and accurate.
Running a Knowledge Quality Program Day to Day
Roll Out Quality Initiatives in Phases
Trying to revamp your entire knowledge quality process all at once can overwhelm your team and halt progress. A phased approach is much more effective.
Start by defining your quality rubric and baseline metrics before bringing AI into the mix. Assign quality gatekeepers to review every new submission against these standards. This reinforces the scoring rubric and ensures consistency. For example, HP implemented this strategy in their Engagement Knowledge Management program by having help desk staff review each submission for quality. Submissions that didn’t meet the standards were flagged for correction, which helped them achieve nearly 100% quality levels within a year [8].
Next, introduce AI scoring as a complement to manual reviews – not as a replacement. Over a 2–3 month period, allow human reviewers to see AI scores alongside their own assessments. This helps build trust in the AI system. Once confidence is established, transition from random sampling to AI-driven anomaly detection, where human reviewers focus only on flagged interactions, such as those with low scores or sudden sentiment changes.
These gradual steps create a solid foundation for ongoing improvement and integrated performance management, as outlined below.
Build Continuous Improvement into the Process
Content quickly becomes outdated without regular maintenance, leading to inconsistent AI responses and a loss of trust among agents [2]. The solution isn’t a massive quarterly overhaul but rather small, consistent updates integrated into weekly workflows. This approach complements earlier AI-driven quality checks by introducing routine, human-led reviews.
Use a RACI model to assign clear roles: senior agents draft and update content, team leads ensure it stays current, subject matter experts verify technical accuracy, and the rest of the support team stays informed about changes [2].
Event-driven updates are just as critical. For example, a product release, pricing adjustment, or policy change should automatically trigger a knowledge review rather than waiting for the next scheduled audit. Pair these updates with validation loops, such as monitoring AI draft edit rates after publication, to refine articles as needed [2]. Regular updates not only keep content relevant but also help maintain strong support performance metrics.
Tie Contributor Performance to Quality Metrics
To build on your quality framework, measure contributor performance based on the impact of their approved content. Simply rewarding high article volume can lead to low-value contributions that inflate numbers without improving results.
Instead, focus on metrics like approved contributions and interaction rates – how often contributors’ articles successfully resolve cases and provide lasting solutions [3]. Another useful metric is Time to Competency (TTC) for new hires. If new agents are ramping up faster, it’s a sign that the knowledge base is doing its job effectively.
"Internal contributions are paramount if you want to implement Knowledge-Centered Service, sustain employee engagement and build a solid organizational culture." – Nouran Smogluk, People Manager [1]
Use aggregate quality scores to guide coaching efforts, targeting specific product areas for improvement [1]. Keeping the focus on just 3–4 key metrics at a time prevents data overload and makes it easier to act on insights that truly matter [1].
Conclusion: Building Scalable B2B Support on High-Quality Knowledge
Measuring the quality of knowledge is a continuous process. Teams that view their knowledge base as a dynamic, evolving tool – rather than a static archive – consistently achieve quicker resolutions, happier customers, and lower support costs.
The numbers back this up. Traditional quality assurance (QA) methods typically review only 2–5% of interactions, whereas AI-driven scoring evaluates 100% of tickets at a fraction of the cost – just $0.01–$0.05 per ticket compared to around $4.00 for manual reviews [4]. As one industry analysis aptly noted:
"The teams that adopt AI-powered QA in 2026 will have a structural advantage in support quality… because reviewing everything beats reviewing 2%." – Supp [4]
It’s also worth noting that knowledge base quality directly impacts about 60% of AI response performance [9]. Even the most advanced AI can’t compensate for outdated, inconsistent, or poorly organized information. To scale AI-native support effectively, maintaining fresh, accurate, and well-structured content is non-negotiable.
Using the strategies outlined earlier – such as quality rubrics, AI-driven scoring, phased rollouts, contributor performance tracking, and continuous improvement cycles – offers a practical path forward. Start small, measure diligently, and let the data guide your decisions. Real-time monitoring, as opposed to sporadic reviews, is the key to setting apart support teams that merely keep pace from those that achieve true scalability.
FAQs
How do I score knowledge quality consistently?
To ensure consistent evaluation of knowledge quality, it’s important to take a well-rounded approach. Focus on several key dimensions, including:
- Coverage: Does the content provide the right answers?
- Quality: Is the information accurate and easy to use?
- Freshness: Is the content current and updated regularly?
- Impact: How does it contribute to faster resolutions and better customer satisfaction?
Create a clear scorecard using these criteria to guide your assessments. Automate processes for checking content accuracy and keeping it up-to-date. Finally, use a unified dashboard to monitor performance regularly, making it easier to identify areas for improvement and maintain high standards over time.
Which 3–4 metrics should I track first?
To ensure the quality of knowledge contributions, it’s important to track specific metrics that provide clear insights. Here are the top ones to focus on:
- Interaction Scores: Metrics like accuracy, tone, and resolution quality can be evaluated using AI tools. These scores offer a snapshot of how effective and user-friendly the interactions are.
- Knowledge Article Relevance: This involves looking at how well articles cover the necessary topics, their correctness, and how easy they are to use. Relevance ensures that the knowledge base remains practical and effective.
- Impact on Outcomes: Analyze how contributions influence key factors like resolution speed and customer satisfaction. This helps connect the quality of knowledge to real-world results.
By keeping an eye on these metrics, you can systematically assess quality and pinpoint areas that need improvement.
How can I prove an article reduced tickets?
To prove that an article helped cut down support tickets, focus on tracking key metrics. For example, measure how often the article successfully resolves issues or look at the drop in related ticket volume over time. Comparing ticket numbers before and after the article was published or updated can also reveal its effectiveness.
AI-driven tools can simplify this process by automating the tracking. These tools can link knowledge base usage directly to ticket resolution rates, giving you clear insights into the article’s impact.







