


When QA scoring varies between managers, it’s not about performance – it’s about inconsistent measurement. In B2B support, where precision is critical, misaligned evaluations can create confusion and erode trust. The solution? A structured QA calibration process to ensure everyone measures quality the same way.
Here’s how to achieve consistent QA scoring:
- Standardize QA Scorecards: Create clear, weighted criteria (e.g., accuracy, tone, completeness) with specific scoring levels and examples to remove subjectivity.
- Run Calibration Sessions: Regularly review and align scores by discussing specific cases, focusing on criteria-level differences, and tracking inter-rater reliability (IRR).
- Track Scoring Consistency: Measure variance at the item level, flagging discrepancies above a 10-point threshold to refine rubrics or retrain reviewers.
- Leverage AI Tools: Use AI for unbiased, scalable evaluations and to identify trends, outliers, and biases in scoring.
- Address Challenges: Reduce bias, update rubrics as policies evolve, and involve new hires in calibration for smoother onboarding.
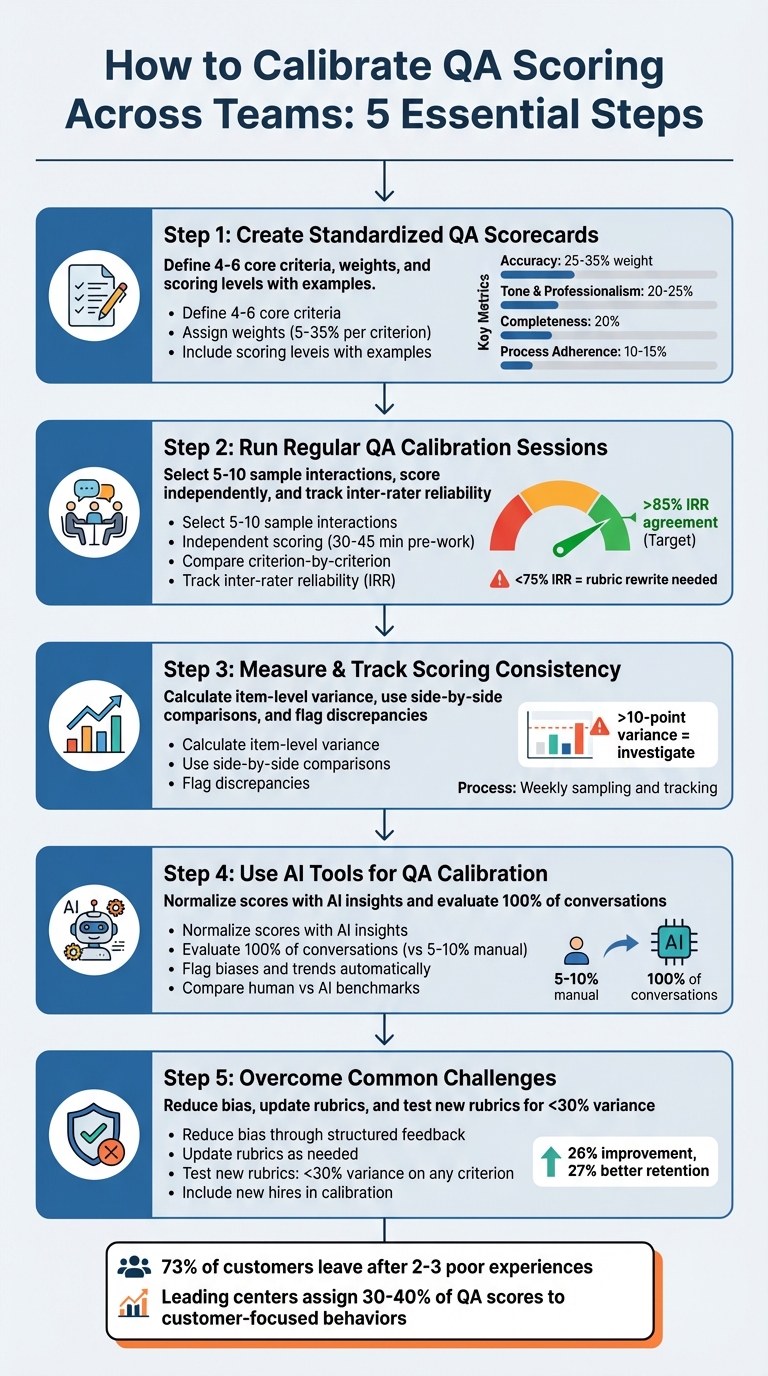
5-Step QA Calibration Process for Consistent Support Team Scoring
Customer Service QA Calibration Sessions – Part 1: Three approaches [Online Course]
sbb-itb-e60d259
Step 1: Create Standardized QA Scorecards
A standardized scorecard takes the guesswork out of quality evaluations. As TeamBench explains:
"A content scoring rubric puts everyone on the same page. It defines exactly what ‘good’ means across multiple dimensions, assigns weights based on priority, and produces a numeric score that removes subjectivity" [3].
Without a shared framework, managers may interpret quality differently, making it tough to compare scores. This structure lays the groundwork for effective calibration sessions down the line.
Define Key Criteria and Metrics
Using standardized metrics ensures all reviewers assess quality the same way. Aim for 4–6 core criteria that cover the main aspects of B2B support. This keeps the process manageable for reviewers [3]. Each criterion should include three key elements: a specific dimension to evaluate, clear scoring levels, and a weight that reflects its importance. For B2B support, focus on these areas:
- Accuracy (25–35% weight): Critical to avoid compliance risks or loss of client trust.
- Tone and Professionalism (20–25%): Ensures interactions align with the brand’s voice.
- Completeness (20%): Measures whether all parts of the customer’s inquiry are addressed.
- Process Adherence (10–15%): Evaluates consistency in following procedures.
- Resolution Quality: Assesses how effectively the issue was resolved [3][4].
Keep each criterion’s weight between 5% and 35% to ensure all factors significantly impact the overall score [3]. For procedural metrics like identity verification or CRM logging, binary checks (1 for yes, 0 for no) work best to eliminate ambiguity [4]. This approach reduces subjective scoring and supports consistent evaluations across teams.
Add Examples and Scoring Guidelines
Detailed examples and clear scoring guidelines make the scorecard practical and actionable. For instance:
"Content sounds unmistakably like the brand. Tone attributes are consistently present. Vocabulary matches the style guide" [3].
This level of detail should apply to every scoring range for each criterion. Include 2–3 annotated examples of both excellent and poor interactions [1][3]. For example, under "Completeness", you might highlight a ticket where the agent addressed all aspects of the customer’s inquiry, contrasted with one where only part of the issue was resolved. Additionally, require that any score below 7 comes with specific feedback pinpointing the problem and offering actionable suggestions for improvement [3].
Step 2: Run Regular QA Calibration Sessions
Once your scorecard is ready, calibration sessions ensure evaluators interpret criteria consistently. These sessions help uncover differences in how managers view standards and align their understanding before these discrepancies impact scores. A well-structured approach is key to avoiding groupthink while highlighting varying interpretations. Here’s how to run effective calibration sessions.
Set a Clear Process for Sessions
Begin by selecting 5–10 interactions that showcase a mix of performance levels – high performers, low performers, and those tricky middle cases that often spark the most discussion. Evaluators should independently score these interactions within 30–45 minutes as pre-work. This step ensures unbiased input and minimizes early influence during group discussions.
During the session, focus on comparing scores for each individual criterion instead of evaluating the interaction as a whole. This method pinpoints exactly where scoring differences arise. If scores differ by more than one scale point, evaluators must explain their reasoning with specific evidence. The goal isn’t to average scores but to refine the scoring criteria so future evaluations are clearer. Bella Williams from Insight7 puts it best:
"A calibration process is not a meeting where people compare scores. It is a systematic method for making your scoring criteria specific enough that different evaluators reach the same conclusion from the same evidence." [5]
Track inter-rater reliability (IRR) as a measure of consistency, aiming for over 85% agreement. [5] If IRR falls below 75% after four sessions, it’s a sign your scoring anchors may need a complete rewrite rather than minor adjustments. [5] For global teams, a variance threshold of a 10-point average delta often triggers mandatory updates to the rubric or additional training for reviewers. [1]
Rotate Facilitators for Different Perspectives
To keep the process dynamic, rotate facilitators across sessions. Sticking with the same facilitator can lead to repetitive patterns and limit new insights. By rotating facilitators, you introduce fresh perspectives and prevent the process from becoming overly rigid. Start with a small group of 2–3 experienced evaluators to establish a foundation before involving larger teams. Smaller groups are particularly effective for reaching consensus quickly, especially when your scoring criteria are still evolving.
Hold monthly sessions to address "evaluator drift", where interpretations shift over time, and to tackle new edge cases as they arise. Keep a shared decision log to record calibration outcomes, notes on score variances, and any changes to the rubric. This creates a clear, auditable record of how your standards evolve. [1]
Step 3: Measure and Track Scoring Consistency
After standardizing your scorecard and running calibration sessions, the next step is to focus on measuring and tracking consistency in scoring. While calibration sessions help uncover disagreements among evaluators, tracking variance over time is what drives real improvement. To stay on top of this, set up a structured weekly process to sample tickets, measure item-level variance, and provide targeted coaching where it’s needed [1].
Calculate Variance in QA Scores
Instead of just looking at overall scores, dig deeper by tracking variance at the item level. Here’s why: two evaluators might both score a ticket at 85%, but one could give high marks for empathy and low marks for policy adherence, while the other does the reverse. That 85% score hides a bigger issue – misalignment on specific criteria. Breaking down variance by areas like empathy, policy knowledge, or resolution quality helps you see where interpretations are diverging [1].
Set a threshold to flag issues – for example, an average variance (delta) of more than 10 points [1]. When you hit that threshold, investigate the root cause. It might be unclear rules, missing scoring anchors, gaps in local policies, or even a need for better training for reviewers. Based on what you find, you may need to update the rubric, add examples, or provide additional coaching. If the variance stays high after multiple sessions, it could mean your scoring anchors need a complete overhaul. These insights pave the way for more detailed comparisons of individual scores.
Use Side-by-Side Comparisons
Variance metrics are helpful, but side-by-side score comparisons can reveal even broader trends. Use tools like Looker Studio to compare score distributions across managers, teams, or even regional sites. For instance, if one site consistently scores 15% harsher than another, it’s likely a calibration issue rather than a true performance difference. Include a few edge cases (2–3) in each session for a more comprehensive review [1].
You can also compare individual reviewer scores to the group consensus to identify outliers – reviewers who might consistently grade too harshly or too generously. These individuals may benefit from extra coaching. To ensure fairness, standardize your sampling process by using a mix of random cases and risk-based cases to avoid bias. Lastly, keep a detailed decision log that tracks changes to your rubric, the reasoning behind those changes, and the dates they take effect. This creates a transparent, auditable record of how your scoring system evolves over time.
Step 4: Use AI Tools for QA Calibration
Manual calibration can provide useful insights, but integrating AI takes consistency to an entirely new level. One of the biggest challenges with manual QA calibration is the risk of human bias, fatigue, and uneven sampling. AI-powered tools tackle these issues by automating the evaluation process, applying consistent decision rules, and analyzing every single interaction – not just a small, manually selected sample. This approach removes subjective grading and ensures a uniform scoring baseline for managers, teams, and even global operations.
Normalize Scores with AI Insights
AI tools, like Supportbench‘s Customer QA AI Bot, bring a standardized approach to scoring. They apply the same logic to every ticket, eliminating the subjective interpretations that often creep into manual reviews. Instead of relying on personal judgment, AI uses predefined criteria to evaluate each interaction consistently across the board [1]. Whether you’re assessing agents in New York or remote teams in other time zones, the scoring remains uniform.
One of the biggest advantages is the sheer scale of coverage. While manual QA typically reviews just 5–10% of tickets, AI evaluates 100% of conversations. This comprehensive analysis helps identify trends and issues that might take weeks – or even months – to surface with manual methods. AI-generated benchmarks also allow you to compare human reviewer scores, making it easier to spot when evaluations are too lenient or overly strict.
Flag Biases and Trends Automatically
AI tools don’t just handle scoring – they also keep an eye on how reviewers are performing. By analyzing individual reviewer patterns against AI-calculated baselines or group averages, you can quickly identify outliers who consistently grade higher or lower than their peers [1]. This helps distinguish genuine performance differences from inconsistencies in calibration.
Beyond scoring, AI automatically flags outliers and categorizes tickets based on factors like site, language, channel, or issue type. This ensures that sampling is fair and representative, avoiding the risk of "cherry-picking" tickets for review. Combined with micro-learning platforms that assign targeted coaching sessions when skill gaps are detected, QA transforms from an occasional audit into an ongoing improvement process. These AI-driven insights work hand-in-hand with manual calibration, creating a consistent and reliable standard across all teams and locations.
Step 5: Overcome Common QA Calibration Challenges
Once you’ve established standardized scorecards and regular calibration sessions, the next step is tackling common obstacles that can disrupt consistent QA practices. Even the most well-designed processes can run into issues like evaluator bias, onboarding challenges, and adapting to new rubrics. The key is to approach these hurdles with practical, repeatable solutions rather than expecting consistency to happen on its own.
Reduce Bias Through Structured Feedback
Evaluator bias often appears as consistently high or low scores from certain reviewers. When disagreements arise during calibration sessions, it’s important to dig into the root causes. Are the rules unclear? Are there gaps in the rubric? Is training falling short? Classifying disagreements this way helps identify whether the issue lies in the rubric itself or in how reviewers are applying it.
If you notice that the average score difference between reviewers exceeds 10 points, it’s time to either revise the rubric or provide additional training [1]. Don’t wait for quarterly reviews to address these discrepancies – track them weekly. Calibration works best as a continuous process rather than an occasional meeting [1]. Another method to reduce bias is independent scoring, where reviewers evaluate tickets without seeing peer scores until after submission. This approach reduces groupthink and anchoring bias, promoting fairness and consistency. In fact, improving fairness can boost performance by 26% and retention by up to 27% [8].
Reducing bias naturally leads to better rubrics that evolve alongside your team’s needs.
Update Rubrics Over Time
Rubrics should never be static. As products evolve, support channels change, and new policies are introduced, scoring criteria need to adapt. Before rolling out a new rubric, test it by sampling calls and measuring variance. If any criterion shows variance greater than one scale point on more than 30% of calls, it’s too ambiguous and needs revision [5]. Strive for an inter-rater reliability (IRR) of 85% or higher – this means evaluators should score within one scale point of each other at least 85% of the time [5].
Onboarding new team members is another area where rubrics play a critical role. Use a “new hire flag” in your QA software to prioritize sampling for recent hires, ensuring they get frequent feedback early on [1]. Include them in calibration sessions as observers so they can learn how edge cases are debated and resolved [7]. Robyn Coppell highlights the value of this approach:
"Including one or two advisors in calibration sessions helps them understand the scoring criteria, how to improve their quality scores, and of what is expected from them" [7].
To maintain consistency, document rubric changes along with their effective dates to ensure long-term data trends remain interpretable [1]. If IRR stays below 75% after four calibration sessions, the issue likely lies with the behavioral anchors rather than the evaluators [5]. As Bella Williams from Insight7 puts it:
"Calibration does not make all evaluators agree on every call. It makes evaluators agree on what the criteria mean so that disagreements become signal… rather than noise" [5].
Conclusion: Build a Culture of QA Excellence
Creating a consistent QA scoring system across managers and teams isn’t a one-time task – it’s an ongoing effort that can reshape your support operations. By implementing standardized scorecards with clear benchmarks, conducting regular calibration sessions, and leveraging AI to minimize biases, you replace subjective judgment with measurable standards. This shift transforms quality assessment from a matter of opinion into a results-driven process. These practices, outlined earlier, form the backbone of a robust QA framework.
But the benefits go well beyond just consistent scores. A unified QA strategy strengthens operational standards while still allowing for necessary regional adjustments [1]. As seen in calibration efforts, this consistency fosters accountability and builds trust among agents, turning feedback into actionable, data-backed coaching [2][6].
Consider this: Over 73% of customers will stop doing business with a brand after just two or three poor service experiences [9]. Leading contact centers now prioritize customer-focused behaviors – like empathy and ownership – by assigning them 30% to 40% of total QA scores, aiming for better customer outcomes [9]. As Robert Haas aptly notes:
"A scorecard that is never tied back to customer satisfaction scores, first contact resolution rates, or churn data is just paperwork" [9].
Make calibration a weekly routine, not an occasional activity [1]. Track discrepancies between reviewers, follow up with QA samples two weeks later to close the coaching loop, and adjust your evaluation criteria as your products and policies evolve. When you tie quality metrics directly to key indicators like CSAT, NPS, and FCR, you turn measurement into meaningful improvement [9].
FAQs
What’s the fastest way to get all managers scoring the same?
One of the fastest ways to get managers on the same page with scoring is by holding calibration sessions. Here’s how it works: Have reviewers independently score the same conversations, then compare their results to pinpoint any differences.
To minimize bias, use blind scoring, where reviewers don’t know who conducted the conversation. Follow this up with group discussions to agree on shared scoring standards.
Consistency improves when you focus on three things: holding calibration sessions regularly, using clear and detailed scorecards, and leveraging AI tools to double-check scoring accuracy. These steps can help teams stay aligned and fair in their evaluations.
How do we measure inter-rater reliability (IRR) in QA?
To evaluate inter-rater reliability (IRR) in quality assurance, start by having multiple reviewers independently assess the same interactions. Once the scores are collected, compare them to identify any differences. Use calibration sessions to discuss these discrepancies and align everyone on the same standards. The goal is to maintain a consistent variance threshold – something like less than 5% is a good target – and keep an eye on any outliers.
AI tools can also be a great asset here. They help identify potential biases and standardize scoring, which ensures that managers and teams stay consistent across the board.
When should we rewrite the QA rubric vs retrain reviewers?
If the evaluation criteria in the QA rubric are unclear, inconsistent, or outdated – especially if they conflict with customer support goals or lead to scoring inconsistencies – rewrite the rubric to address these issues. When the rubric itself is solid but inconsistently applied due to misunderstandings or lack of familiarity, focus on retraining reviewers to ensure proper usage. Calibration sessions can also help reviewers align their understanding and apply the rubric consistently, avoiding the need for a complete overhaul.







