If you merge support teams without one shared setup, service slows down, SLA reporting gets messy, and customers have to repeat themselves. The fix is simple to say, but hard to do well: I would audit both helpdesks, set one set of rules, migrate in phases, keep the old system read-only for a set time, and track results from Day 1.
Here’s the short version:
- Audit first: tools, queues, SLA rules, fields, workflows, portals, inboxes, KBs, and integrations
- Standardize the core: one taxonomy, one priority model, one reporting model, and one account view
- Keep some legacy items in place for a short time: open SLA-bound tickets, regulated flows, and old integrations
- Migrate in stages: users, accounts, open tickets, comments, attachments, then a delta sync
- Control cutover risk: freeze config changes 48–72 hours before go-live, switch the old desk to read-only, and tag migrated tickets by source
- Train agents early: during test migration, not the night before launch
- Measure results: FRT, resolution time, FCR, SLA attainment, backlog, throughput, handoffs, CSAT, and total tooling cost
A few numbers stand out. The article notes that tool switching can cut agent output by up to 25%, and 83% of data migration projects fail or run late or over budget. That’s why clean data, clear field mapping, and phased cutover matter so much.
What I like about this approach is that it keeps the goal plain: one system of record, one workflow, and one account history. That is what helps you protect support quality after a deal closes.
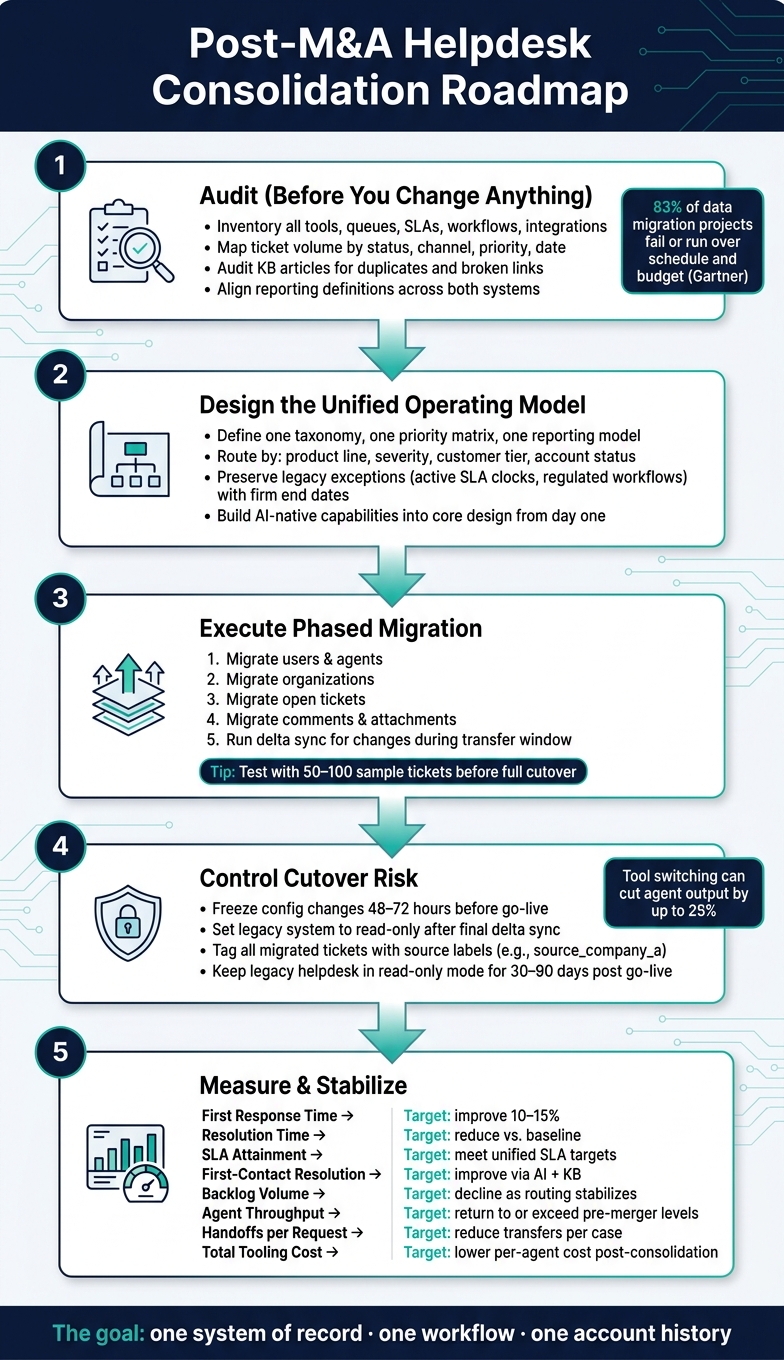
Post-M&A Helpdesk Consolidation: Step-by-Step Migration Roadmap
ABCs of M&A Technology Integration
sbb-itb-e60d259
Audit the current support environment across both companies
Map the combined environment before you change anything. That first pass matters more than most teams expect. According to Gartner, 83% of data migration projects either fail or go over schedule and budget [2].
Inventory tools, queues, SLAs, workflows, and integrations
Start with a full catalog of every active helpdesk, support inbox, portal, and queue across both companies. For each system, note who has admin access, which agents and teams are active, and what permissions they hold.
Then map the working logic behind each setup: workflow rules, automations, escalation paths, business-hours rules, and SLA policies. You also need to document how each system tracks Created, Updated, and Resolved timestamps [1].
Before you compare SLAs, normalize priority labels [1].
That sounds small, but it isn’t. One team’s High may be another team’s Urgent, and if you compare them as-is, you’ll end up matching apples to oranges.
Next, inventory every connected system and channel, including:
- CRM
- ERP
- billing
- Slack
- project management tools
- email forwarding
- chat widgets
- web forms
- custom API connections
This map should show where you can standardize right away and where older setup choices still need to stay in place.
Audit ticket data, knowledge bases, and reporting definitions
Use usage reports, not old internal docs. On paper, a system may look neat. In practice, teams often find unused custom fields, dead tags, and automations nobody has touched in months. If you bring all of that into the new system, it becomes clutter from day one [5].
For ticket data, break volume down by status, channel, priority, and date range. Also look for duplicate contacts and organizations across both systems [3]. Closed tickets usually make up most of the data load, so archive tickets older than two years unless retention rules say they must move [1] [6].
Give the knowledge base the same level of scrutiny. Check for duplicate articles, broken internal links, old media files, and content that has different internal and external access rules. Preserve knowledge-to-ticket relationships so past resolution patterns stay intact [1].
Audit reporting definitions side by side too. If naming conventions and status models differ, your post-consolidation KPIs will get distorted fast [1]. Those gaps show what you can standardize now and what needs to wait.
Build a current-state comparison table and consolidation checklist
Use the comparison to split immediate standardization from temporary coexistence. For example, an active SLA clock on an open enterprise ticket can’t be interrupted mid-migration. A redundant tag taxonomy, on the other hand, can usually be cleaned up right away.
| Audit Category | Findings Favoring Standardization | Findings Requiring Coexistence |
|---|---|---|
| Custom Fields | Unused or dormant fields; redundant data points | Fields tied to active legacy integrations |
| SLAs & Routing | Overlapping priority levels (e.g., "High" vs. "Urgent") | Open tickets with legally-mandated SLA clocks |
| Knowledge Base | Outdated articles; duplicate how-to content | Proprietary product docs still in transition |
| User Roles | Identical support tiers and permission needs | Specialized teams with unique, regulated access |
| Data Privacy | Duplicate customer profiles across both systems | Regional data residency requirements (GDPR/CCPA) |
Use this table to separate cleanup work from legacy constraints.
At a minimum, your consolidation checklist should confirm:
- admin access is verified on both systems
- ticket volume by status is documented
- SLA definitions are mapped to one standard
- integrations are inventoried and owners are identified
- KB articles are reviewed for duplicates and quality
- reporting metric definitions are aligned
Use the checklist to decide what moves now and what stays in parallel. Use it as the input for the future-state operating model and migration plan. Once the baseline is clear, define the future-state workflow.
Design the unified support operating model
Decide what to standardize now and what to preserve temporarily
Once the audit is done, don’t try to standardize everything in one shot. Start with the parts that set the rhythm for the whole team: routing, triage, and reporting. That means one taxonomy, one priority matrix, and one reporting model. Use the audit findings to set the default rules, then carve out short-term exceptions where needed.
Some things need to stay in place for a while, plain and simple. If changing them too soon would disrupt service delivery, preserve them for the transition period. That includes open enterprise tickets with active SLA clocks, regulated workflows, and custom objects like asset links, parent-child hierarchies, and entitlements [1]. Keep the source helpdesk in read-only mode during the move so agents can still check history that hasn’t been migrated yet [6]. And don’t let exceptions drift forever. Give each one a firm end date so "temporary" doesn’t turn into long-term mess.
Define the future-state workflow, routing model, and knowledge structure
The future-state model should push every request into one system of record. That includes unofficial channels like Slack DMs and personal email, so work doesn’t disappear outside the queue [4]. Build routing around the variables that matter most in B2B support:
- product line
- severity
- customer tier
- account status
Each requester also needs to be tied to the right account. That’s how you keep B2B account context intact and protect reporting accuracy across both inherited businesses [3][2].
For knowledge management, keep the KB structure, not just the article copy. Hold on to categories, language variants, and internal links because they also feed support routing, self-service, and AI-assisted workflows after migration [1][2]. Internal runbooks and customer-facing articles should stay separate, with access controls in place so customers only see what’s meant for them. Think of that structure as the data layer behind AI routing, summaries, and search.
Build AI-native capabilities into the core design
AI shouldn’t be bolted on later. It needs to be part of the core design from day one. Build in ticket summarization, duplicate detection, routing suggestions, KB consolidation, and escalation-risk flagging so the unified model works with full context as soon as agents take over customers from both legacy systems [1][2].
In Supportbench, these features sit inside the same system that handles customer context, queues, SLAs, escalations, roles, permissions, and the knowledge base. AI case summaries, case history search, AI-generated knowledge articles, predictive CSAT and CES, and dynamic SLAs can all run from one shared platform. That cuts down tool sprawl, makes consolidation easier to govern, and gives teams a support stack that’s simpler to run, easier to train on, and better set up for post-M&A reporting.
Execute migration and change management with minimal disruption
Plan the phased migration of tickets, email, portals, and knowledge
Once the operating model is set, move into cutover in phases. Skip the big-bang approach. Start with one channel or one customer segment, make sure it works end to end, and then expand.
The order of the technical move matters. Bring over users and agents first, then organizations, then open tickets, and finally comments and attachments so you don’t end up with orphaned records [5][2]. Run a sample migration of 50 to 100 tickets across different date ranges and statuses. Then check that internal notes and attachments show up the way they should before the full cutover [6][2]. After the main migration, run a delta sync to pull in anything created or changed during the transfer window [7][6].
Control dual-running risk during the transition period
The overlap period is where things often go sideways. After the final delta sync, set the legacy system to read-only, tag migrated tickets, and stop new work from flowing into the old queue [6][3]. Give every migrated ticket a source label, such as source_company_a or legacy_system_b, so reporting stays clean during the transition [2].
Those labels should also stay in reporting and AI workflows, so legacy work and unified work remain easy to tell apart during stabilization. Put a configuration freeze in place on both systems 48–72 hours before cutover. A last-minute change to a field or status can throw off your mapping fast [3].
To protect ticket ownership, SLA continuity, and account-level routing across both inherited businesses, use read-only mode and source labels together, not as separate steps.
Keep the legacy helpdesk available in that restricted state for 30 to 90 days after go-live so late replies to old threads and long-running cases still route the right way [6].
Use a migration risk table, training plan, and rollout checklist
Once the overlap period is under control, shift attention to agent training and rollout checks. Training should begin during the test migration phase, not the day before go-live. Give agents a quick-reference guide that shows the old workflow next to the new one, so the new process feels familiar before customers ever notice a change [7][6]. Gather structured feedback at Day 7 and Day 30 after go-live [7][6].
The table below covers the risks that tend to do the most damage during dual-running and the first stretch after migration, along with the mitigation actions and owners that should be assigned before cutover.
| Risk | Impact | Mitigation Action | Owner |
|---|---|---|---|
| Data loss | Missing attachments or conversation history | Run a full UAT migration with real data; verify counts post-sync | Technical Lead |
| Broken routing | Tickets land in wrong queues or go unmonitored | Manually rebuild and test all triggers and automations in the new system | Support Ops |
| Duplicate tickets | Agents work the same case in two systems | Set the legacy system to read-only; apply source-specific tags | Project Lead |
| Missed escalations | SLA breaches | Define fallback paths and monitor the queue 24/7 for the first 48 hours | Support Lead |
| Reporting gaps | No clean baseline for post-merger KPIs | Map original ticket IDs to a searchable custom field in the new system | Reporting Lead |
| Portal issues | Customers can’t access ticket history | Redirect legacy help center URLs to the unified portal | Web/IT Team |
Before you flip the switch, run through this rollout readiness checklist so nothing major slips through. Keep source labels and original ticket IDs searchable in the new system. That makes cross-system summaries, duplicate detection, and post-go-live reporting much easier.
- [ ] Outbound notifications disabled during historical import
- [ ] Email forwarding, chat widgets, and web forms pointing to the new instance
- [ ] CRM, billing, and Slack integrations re-authenticated in the new environment
- [ ] Quick-reference guides distributed and training completed
- [ ] Rollback procedure documented with clear go/no-go triggers
- [ ] Legacy admin credentials verified for post-migration read-only reference
Measure results and stabilize the new helpdesk model
Track KPI baselines before and after consolidation
Before go-live, lock in baselines for FRT, resolution time, FCR, SLA attainment, backlog, throughput, handoffs, CSAT, and total tooling cost. Then, once the cutover is done, compare the new setup against those pre-migration numbers. That side-by-side view tells you if the merged helpdesk is getting better or just getting by.
One detail matters more than it might seem: keep original ticket timestamps during migration. If you don’t, your multi-year reporting gets messy fast, and trend lines stop being comparable [1].
For cost, look at total tooling spend across both companies before consolidation. That includes licenses, per-agent fees, training, and maintenance overhead. In plain terms, don’t just compare subscription prices. Compare the full bill.
| Metric | What to Baseline | 90-Day Target |
|---|---|---|
| First Response Time | Average per company pre-merger | Improve by 10–15% versus baseline |
| Resolution Time | Median across both ticket systems | Reduce versus pre-merger baseline |
| SLA Attainment | % of tickets meeting SLA per company | Meet unified SLA targets |
| First-Contact Resolution | FCR rate per legacy system | Improve via AI detection and KB coverage |
| Backlog Volume | Open tickets at cutover | Decline as routing stabilizes |
| Agent Throughput | Tickets handled per agent | Return to or exceed pre-merger levels |
| Handoffs per Request | Number of transfers per case | Reduce the number of handoffs per request |
| Total Tooling Cost | Combined license spend in USD | Lower per-agent cost post-consolidation |
Use AI insights to improve quality after go-live
After the first 30 days, use those baselines to go after the biggest pain points first.
Escalation-risk flagging helps support leads spot cases that are heading toward an SLA breach before that breach happens. AI-generated case summaries help agents who pick up transferred tickets get up to speed without digging through a long thread. AI-based FCR detection cuts down on manual review. And knowledge base answers can appear during active tickets, which helps a lot right after a merger, when agents are still learning the combined product line and policy setup.
AI pattern detection also shows which issues should be deflected with a new article or a workflow change. That’s often where the merged team starts to find easy wins.
Use those signals to tighten routing and prioritization, improve deflection, and clean up escalation handling.
Conclusion: the shortest path to one support model after M&A
Post-M&A helpdesk consolidation follows a clear sequence: audit everything first, standardize the operating model around what already works, migrate in phases with historical data loads and delta syncs, manage agent change closely, and measure both customer experience and cost from day one. Skip one of those steps, and that’s usually where projects stall, drift, or run over budget.
The strongest consolidations treat the platform as the shared system of record for support, knowledge, routing, and reporting. When support context, workflows, knowledge, routing, reporting, and AI sit in one place, the overhead from fragmented systems starts to fall away.
That’s the goal: not just fewer tools, but one support model that gives every customer a consistent, accountable experience, no matter which company they first signed with.
FAQs
How long does helpdesk consolidation usually take after M&A?
Helpdesk consolidation after a merger or acquisition is usually not a year-long project. If you standardize the core pieces first and lean on AI automation where it makes sense, many teams can finish the move in about 90 days.
The exact timeline depends on data complexity and the size of the organization. In most cases, the teams that get this right have a clear target operating model, clean data, the right core integrations, agents who are ready to work in the new setup, an upfront audit, a controlled migration plan, and a post-launch hypercare period.
What data should we avoid migrating into the new helpdesk?
Don’t carry over clutter that gives agents, reporting, or compliance nothing useful. Leave behind duplicate customer records, abandoned tags, unused custom fields, stale knowledge base articles, inactive agent accounts, and old tickets that sit outside your retention window.
The better move is to sort data into two groups: what you need to keep in the new system, and what can live in an external archive or be deleted. That way, the new setup stays clean and easy to manage.
How do we keep SLAs and customer history intact during cutover?
Treat cutover as a system handoff, not just a data dump. SLA logic often works differently from one platform to another, so it’s better to rebuild policies, triggers, and routing rules by hand in the new system instead of forcing a direct transfer.
Use delta migration to pull in records that were created or updated during the bulk migration. That should include one last sync in the final few hours before cutover. During import, turn off outbound notifications so users don’t get flooded with accidental alerts. Then run full-scale UAT with real data to make sure record history and timestamps remain intact.