


If you manage support for GovTech clients, FedRAMP compliance and data residency rules are non-negotiable. Without them, federal contracts are out of reach. Here’s what you need to know:
- FedRAMP Compliance: Federal cloud providers must meet strict security standards. As of July 2025, only 451 companies/products achieved this. Starting March 1, 2026, FedRAMP enforces Secure Configuration Guides with penalties for non-compliance, including removal from the marketplace by July 1, 2026.
- Data Residency Rules: Federal data often must stay in the U.S. For regulations like ITAR, even support personnel must be U.S. citizens or permanent residents. Global support models typically don’t meet these requirements.
- AI and Compliance: AI tools introduce risks if not configured for data residency. Self-hosting AI or using zero data retention options can help ensure compliance.
- Continuous Monitoring: FedRAMP requires monthly scans, annual assessments, and detailed audit trails for all support actions involving federal data.
Non-compliance can lead to legal issues, financial penalties, and loss of federal business. This guide explains how to align your support workflows with these standards while integrating compliance into everyday operations.
How to do a FedRAMP Security Assessment and Authorization | Drafting Compliance Ep. 10
sbb-itb-e60d259
FedRAMP Compliance: Requirements and Baseline Selection
FedRAMP Baseline Levels: Controls, Use Cases, and Impact Comparison
FedRAMP, short for the Federal Risk and Authorization Management Program, is the standardized framework that dictates how cloud service providers (CSPs) handle federal agency data. Built on NIST standards, it classifies systems by their potential impact levels. Without FedRAMP authorization, cloud providers are locked out of the federal marketplace.
The authorization process can take anywhere from 6 to 18 months, with costs varying based on the chosen baseline – Low, Moderate, or High. For context, achieving Moderate authorization often costs two to three times more than Low authorization, while High authorization expenses can be 30% to 50% higher than Moderate [10]. Because of these financial and resource investments, selecting the right baseline at the outset is critical. Understanding the baseline levels is the first step in aligning your system with the appropriate controls.
FedRAMP Baseline Levels Explained
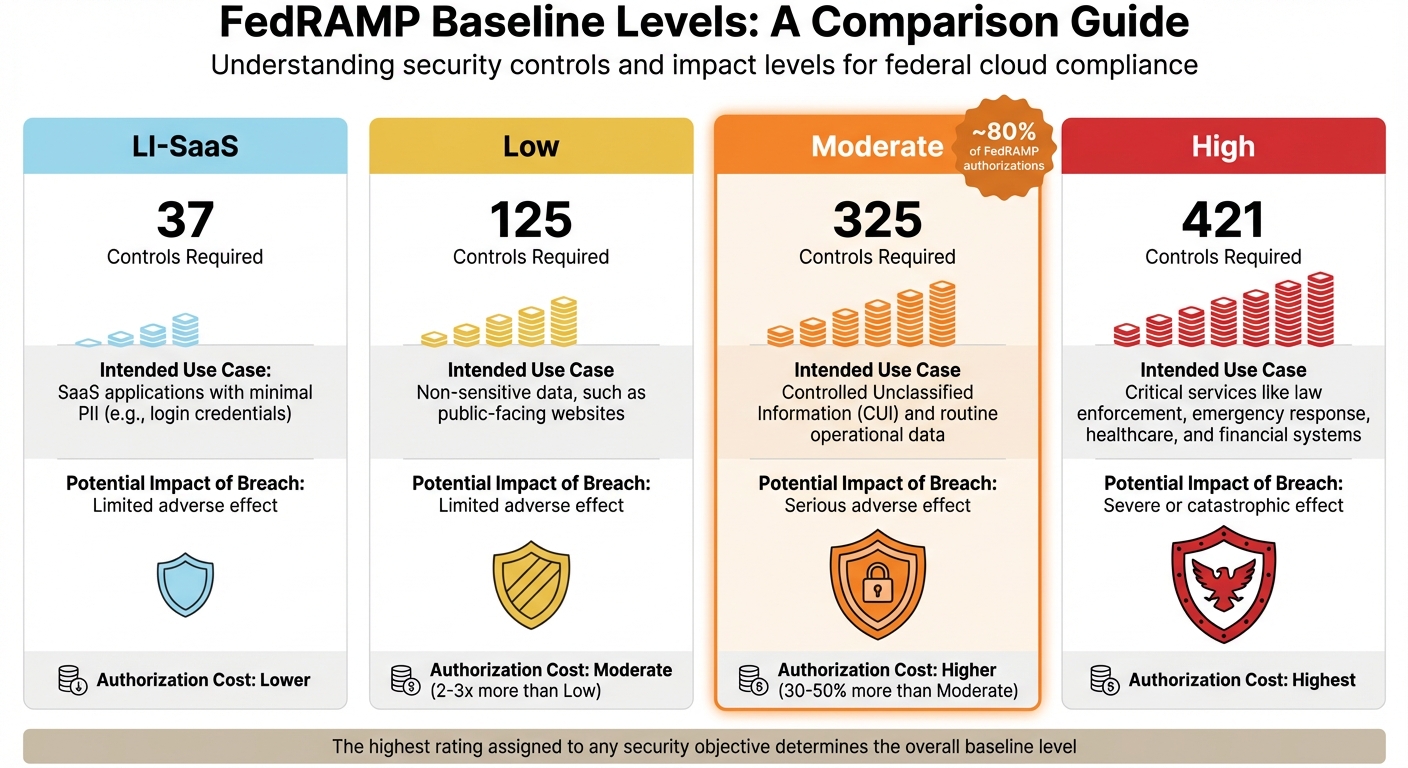
FedRAMP outlines four baseline levels, each corresponding to specific use cases and security requirements. The highest rating assigned to any security objective determines the overall baseline level [5].
| Baseline Level | Controls Required | Intended Use Case | Potential Impact of Breach |
|---|---|---|---|
| LI-SaaS | 37 | SaaS applications with minimal PII (e.g., login credentials) | Limited adverse effect |
| Low | 125 | Non-sensitive data, such as public-facing websites | Limited adverse effect |
| Moderate | 325 | Controlled Unclassified Information (CUI) and routine operational data | Serious adverse effect |
| High | 421 | Critical services like law enforcement, emergency response, healthcare, and financial systems | Severe or catastrophic effect |
Interestingly, Moderate impact systems dominate the FedRAMP landscape, accounting for roughly 80% of authorized applications [7][12]. For many GovTech organizations, the Moderate baseline strikes the right balance. As Robert Dougherty, a Regulatory Compliance Expert at Kiteworks, explains:
"Selecting the right level involves balancing security investment against market opportunity, with Moderate offering the optimal combination for most providers by enabling access to the largest segment of federal spending." [10]
While organizations can use FIPS 199 templates to categorize their systems, the final impact level is determined by the federal agency customer (Authorizing Official). These officials may have varying risk tolerances and mission-specific requirements [12]. Early collaboration with agency partners is essential to finalize the impact level classification before starting documentation [12].
With baseline levels understood, the FedRAMP process moves through four structured phases.
4 Phases of FedRAMP Authorization
The FedRAMP authorization journey is divided into four distinct phases, each with specific activities:
| Phase | Key Activities |
|---|---|
| 1. Documentation (Preparation) | CSP categorizes the system, implements necessary controls, and creates a detailed System Security Plan (SSP) [9][12] |
| 2. Assessment | A Third-Party Assessment Organization (3PAO) evaluates the system and produces a Security Assessment Report (SAR) [9][11] |
| 3. Authorization | The agency reviews the security package and grants Authority to Operate (ATO) [9][11] |
| 4. Continuous Monitoring | CSP conducts monthly vulnerability scans, annual assessments, and updates the Plan of Action and Milestones (POA&M) [9][11] |
The Documentation phase often presents the most delays. Accurately defining your data flow and authorization boundary is crucial, as missteps here can lead to significant setbacks [12]. Preparing for authorization typically requires a team with expertise in project management, system architecture, technical writing, and customer relationship management (CRM) [12].
During the Assessment phase, common issues include missing multi-factor authentication (MFA), outdated software, and reliance on external services that lack FedRAMP authorization [12]. Another frequent pitfall is failing to use FIPS 140 validated cryptographic modules for securing data in transit and at rest [12]. Kiteworks, for example, achieved FedRAMP Authorization at the Moderate impact level in March 2025. Its Private Content Network employs FIPS 140-3 validated cryptography and integrates email, file sharing, and SFTP [10].
One way to simplify the process is by hosting your solution on an already FedRAMP Authorized Infrastructure-as-a-Service (IaaS) or Platform-as-a-Service (PaaS) [12]. This allows you to leverage existing security controls rather than building everything from scratch.
These phases also affect support operations, as maintaining compliance requires detailed security logs and timely vulnerability remediation – key expectations for GovTech customer support.
Continuous Monitoring Requirements
FedRAMP compliance isn’t a one-and-done achievement. Continuous monitoring is essential to maintain authorization in sensitive federal environments. CSPs must uphold their security posture through regular activities:
| Requirement | Frequency | Description |
|---|---|---|
| Vulnerability Scans | Monthly | Scan operating systems, databases, and web applications for vulnerabilities [11] |
| POA&M Updates | Monthly | Update the Plan of Action and Milestones to track risk remediation progress [11] |
| Executive Summary | Monthly | Provide a summary of the security posture to Authorizing Officials [11] |
| Security Testing | Annual | Conduct annual testing of a subset of controls via a 3PAO to verify compliance [11] |
Support operations play a critical role in compliance. Every interaction involving federal data must be logged with precise, time-stamped audit trails. These logs are vital during continuous monitoring reviews.
The consequences of non-compliance are severe. Starting in March 2026, FedRAMP enforces the Secure Configuration Guide (SCG) requirement. Providers failing to comply by July 1, 2026, risk removal from the FedRAMP Marketplace and a three-month ban on relisting [8]. To avoid penalties, the SCG must clearly define administrative account settings and their security implications [8].
Data Residency Requirements: Meeting Jurisdictional Standards
FedRAMP ensures federal operations are secure, but data residency rules dictate where and how federal data can be stored and accessed.
Federal Data Residency Mandates
Data residency refers to the physical location of stored data, while sovereignty involves governing that data under local laws. For GovTech organizations, federal mandates impose strict residency rules. One of the most stringent is ITAR (International Traffic in Arms Regulations), which requires defense-related data to be stored in the U.S. and accessed only by "U.S. persons" – citizens or permanent residents [15]. This means global support models cannot meet ITAR compliance standards.
FISMA (Federal Information Security Management Act), while not always explicit about residency, often requires sensitive data to stay within U.S. borders to meet security requirements [14]. In practice, this makes international support infrastructures non-compliant for handling sensitive federal workloads.
Adding complexity, the U.S. CLOUD Act allows U.S.-based companies to be compelled to provide access to data stored overseas. As PremAI explains:
"The legal jurisdiction follows the company, not the data center" [4].
This creates conflicts with frameworks like GDPR, which demand stricter sovereignty [16].
Support operations face unique challenges under these mandates. For ITAR-compliant systems, every support agent must be a U.S. person, and metadata – like logs, billing records, and API activity – must remain within U.S. jurisdiction [15]. As Open Edge points out:
"A global support organization disqualifies a platform from ITAR use, even if the data resides in the United States" [15].
Non-compliance can lead to hefty penalties. For instance, Meta was fined €1.2 billion in 2023 for transferring EU user data to the U.S. [4]. The growing focus on sovereignty is reflected in the sovereign cloud market, projected to soar from $154 billion in 2025 to $823 billion by 2032 [16]. These legal frameworks are the cornerstone for designing secure and compliant workflows.
Building Compliant Data Handling Workflows
To meet residency standards, start by implementing regionally isolated systems that ensure storage, computation, and monitoring all occur within the same jurisdiction. A data flow audit is a crucial first step. AI introduces additional residency checkpoints, including training data (where models are built), inference residency (where computations occur), fine-tuning data, and log storage [4]. Each step must adhere to jurisdictional rules.
| AI Operation | Output | Compliance Implication |
|---|---|---|
| API Inference | Prompts, completions, tokens | Computation must align with residency rules |
| Fine-Tuning | Training examples, model weights | Data must be processed locally |
| RAG/Embeddings | Document chunks, vectors | Vector databases must remain in-region |
| Observability | Payloads, logs, errors | Monitoring tools must stay within jurisdiction |
The distinction between control plane and data plane is critical. Even if application data resides in the U.S., metadata – like API logs or billing records – flowing through global systems can breach compliance [15]. Systems need to ensure metadata stays in the same jurisdiction as primary data.
For support workflows, adopt "deny by default" egress policies to prevent unintentional data exposure when agents query systems or access logs. Instead of retrofitting global systems with regional safeguards, build full-stack environments tailored to each jurisdiction [17].
Support and engineering teams working on regulated workloads must not only be U.S.-based but also operate under laws governing federal data access [15][16]. This goes beyond location – it’s about ensuring compliance with legal frameworks.
In November 2025, Google Cloud secured a major NATO contract to deliver AI-enabled sovereign cloud services. Using Distributed Cloud air-gapped environments, they maintained strict data residency for defense applications [16]. This highlights the importance of advanced compliance measures for GovTech operations.
Configuring AI Support Tools for Data Residency Compliance
After establishing compliant workflows, it’s essential to align AI tools with residency standards. 67% of enterprises cite data residency as the main barrier to scaling AI globally [18]. AI systems can create hidden data flows that may conflict with jurisdictional rules.
The first step is pinpointing where your AI tools send data. Many support platforms rely on third-party AI services for features like ticket summarization, sentiment analysis, or response suggestions. If these services process data outside the required jurisdiction, compliance is compromised – even if the primary data stays local.
Activate Zero Data Retention (ZDR) on AI APIs. Providers like OpenAI and Anthropic offer ZDR options to ensure prompts and completions are not stored beyond the session [4]. This prevents data from persisting outside approved regions.
For sensitive workloads, self-hosting AI tools may be necessary. Organizations processing over 2 million tokens daily often find private inference engines like vLLM or TensorRT-LLM both cost-effective and compliant [4]. Running inference locally also boosts performance by up to 45% compared to cross-region execution [18].
Confidential computing provides another layer of security. Using hardware-protected enclaves, such as NVIDIA H100 Confidential Computing, sensitive data remains encrypted even during processing [4]. This ensures compliance without risking unauthorized access.
Ensure all AI-related data paths – such as API logs, vector databases, and observability records – remain within the designated jurisdiction. A 2023 incident with Samsung Electronics underscores the risks: employees accidentally leaked sensitive information through ChatGPT, bypassing residency controls [4].
Configure regional endpoints explicitly rather than relying on defaults. Examples include Azure’s EU Data Boundary and AWS’s European Sovereign Cloud [4][16]. Microsoft’s commitment to processing Microsoft 365 Copilot interactions within specific countries by 2026 reflects the growing demand for localized AI solutions [16].
When working with GovTech support operations, treat AI configuration as a compliance-driven task, not a convenience feature. Proper planning ensures both adherence to legal standards and efficient operations.
Aligning Support Operations with Compliance Standards
Compliance isn’t just a box to check for the security team – it’s woven into every interaction your support team has with federal data. Every ticket, log entry, and escalation must align with regulatory requirements. The trick lies in making compliance part of the daily workflow, not an afterthought. Here’s how to embed these practices seamlessly into your support operations.
Building Compliance into Support Workflows
To stay ahead of audits, bake compliance directly into your workflows. One way to do this is through Action-Level Approvals. Sensitive tasks like data exports, privilege escalations, or configuration changes should require manual review and approval before proceeding. Instead of granting blanket permissions to support agents, each action pauses for verification. As hoop.dev puts it:
"Action-Level Approvals ensure that key operations like data exports, configuration edits, or user-role changes still pause for a person’s explicit review" [19].
This approach creates detailed audit trails, logging user identity, timestamps, and IP addresses – key details regulators expect [3].
Another tool is data tagging. By tagging sensitive data at the point of ingestion, automated systems can apply masking, encryption, or routing rules without needing manual oversight. For example, when a ticket contains personally identifiable information (PII) or federal data, these tags trigger downstream protections, reducing the risk of accidental exposure [20].
Support teams should also maintain Secure Configuration Guides (SCG) for administrative accounts. These guides help ensure proper decommissioning processes and adherence to secure settings [13].
AWS has also made strides in compliance automation. In August 2024, they introduced Config conformance packs for FedRAMP High in AWS GovCloud. These packs simplify compliance by automating security control assessments across environments and feeding results into AWS Security Hub for centralized reporting. This reduces manual effort while providing continuous compliance visibility [6].
Support Leadership’s Role in Compliance
Support leaders play a crucial role in translating technical compliance requirements into everyday practices. With 93% of enterprise executives in 2026 identifying AI sovereignty as a key governance issue, managing data flow and tool selection has become more critical than ever [22].
One way to address this is by establishing clear policies for AI usage. For instance, creating whitelists and blacklists for AI tools can prevent sensitive data from being shared with unauthorized platforms [22]. Samsung’s decision to ban ChatGPT in May 2023 is a cautionary tale. Following incidents where employees leaked semiconductor source code and internal meeting transcripts, an internal survey revealed that 65% of employees saw generative AI tools as major security risks [4].
Integrating approval workflows into tools like Slack or Teams can streamline compliance without slowing down support operations. These workflows allow for real-time, traceable reviews. Additionally, automated conformance packs provide near real-time compliance scores, helping teams address configuration drift before it becomes a full-blown violation. For context, building a FedRAMP-compliant environment can cost 30–50% more than standard setups [2].
Leadership responsibilities also extend to leveraging AI tools to enhance compliance oversight.
Using AI for Compliance Monitoring
AI can take on the heavy lifting for compliance, freeing up support teams to focus on customer needs. Automated evidence gathering is one example – it tracks policy drift, validates encryption, and collects documentation for audits like FedRAMP and SOC 2 without requiring manual input [19][21]. AI can also monitor resources in near real-time, checking them against FedRAMP High’s 421 security controls across 17 categories. If configuration drift occurs, the system flags it immediately, preventing issues before they escalate [6].
For AI agents handling privileged tasks, cryptographic evidence chains can ensure tamper-proof records. Using SHA-256 hash chains, these records document every decision and action, aligning with the NIST AI Agent Standards introduced in February 2026. These standards emphasize oversight and verification for autonomous systems [1].
AI tools also boost efficiency. For example, AI-assisted translation and document processing can increase support throughput by 6–8× when paired with human verification [3]. However, these gains only matter if the AI infrastructure respects data residency rules. As PremAI points out:
"The era of ‘move fast and figure out compliance later’ is over for AI" [4].
Configuring AI tools to enforce data residency – ensuring local processing for inference, fine-tuning, and logging – is increasingly essential. By late 2025, 73% of enterprises cited data privacy and security as their top AI-related risk concern [4]. This makes proper AI configuration not just a technical need but a leadership priority.
Conclusion
Meeting FedRAMP and data residency compliance standards is non-negotiable if you want to do business with federal agencies. Without FedRAMP authorization, you’re essentially shut out of a market valued in the hundreds of billions of dollars annually [24]. But securing this authorization isn’t a one-and-done effort – it requires constant oversight and operational commitment [23].
This is where AI tools can make a huge difference. Automated features like evidence gathering, real-time configuration monitoring, and AI-driven conformance packs significantly cut down on manual work while keeping your organization prepared for audits. For example, companies using AI-powered compliance platforms have reduced vulnerability backlogs by 70% [23]. When combined with human verification, these tools can increase support capacity by 6–8× while maintaining strict adherence to regulations [3]. These efficiencies are especially valuable when navigating the added complexities of data residency rules.
Data residency adds another layer of difficulty by dictating where data is stored and which legal frameworks apply. The US CLOUD Act, for instance, extends its reach beyond U.S. borders, meaning that choosing a regional deployment doesn’t necessarily ensure full data sovereignty [4]. For organizations handling high data volumes, self-hosting large language models can be both a compliant and cost-effective solution [4].
By embedding compliance into everyday workflows – through measures like action-level approvals, data tagging, and AI-driven monitoring – organizations can turn regulatory demands into operational strengths rather than hurdles. As TrustCloud aptly puts it:
"FedRAMP is more than a security checkbox. It opens the door to one of the largest buyers in the world: the U.S. federal government" [24].
Although the upfront costs for FedRAMP authorization can range from $400,000 to over $2 million [24], the alternative is far more expensive. Non-compliance could mean exclusion from federal contracts or fines as high as 7% of global annual revenue under laws like the EU AI Act [4]. By prioritizing compliance from the beginning, you not only meet regulatory requirements but also position your organization for sustainable growth.
FAQs
Which FedRAMP baseline should we choose?
The choice of the right FedRAMP baseline hinges on how sensitive your data is and your compliance requirements. If you’re handling highly sensitive or classified information, the FedRAMP High Baseline is your go-to, as it offers more rigorous security measures. On the other hand, the FedRAMP Moderate Baseline is the most widely adopted option, providing access to a broader federal market while maintaining less stringent controls. Keep in mind that recent changes to secure configurations could also play a role in shaping your decision.
How do we keep support access ITAR-compliant?
To comply with ITAR regulations, it’s essential to handle defense-related technical data with the utmost care. Access to this data must be strictly limited to U.S. persons as defined by ITAR. Additionally, storing this information on U.S.-based infrastructure is a critical step in safeguarding it.
Key measures include implementing strict access controls to ensure only authorized individuals can interact with the data. Using ITAR-compliant solutions equipped with features like audit trails and encryption adds another layer of security. These steps are crucial for preventing unauthorized access and maintaining compliance, particularly during support processes that involve sensitive defense-related information.
How can we use AI without breaking data residency?
To ensure AI complies with data residency rules, focus on creating policy-aware AI architectures that ensure data remains within specified jurisdictions. Use automated compliance processes and adopt frameworks like FedRAMP to monitor and safeguard data location and security. It’s also crucial to map out regional data residency requirements, ensuring AI workflows adhere to local regulations, including rules on data localization and sovereignty.
Related Blog Posts
- How do Canadian data residency requirements affect helpdesk selection?
- What does “Buy Canadian” mean for software and SaaS procurement in Canada?
- How do you evaluate “foreign access risk” when choosing a US vs non-US helpdesk?
- How do tariffs and cross-border risk change SaaS vendor selection for Canadian teams?







